Can an open-source MQTT broker handle one million messages per second for persistent sessions? TBMQ 2.x proves it can! Even more importantly, it achieves this with no single point of failure and ensures no data loss, even when hardware fails, making it a robust self-hosted MQTT broker solution for IIoT applications.
This article dives into the architectural decisions and performance improvements that define the recent 2.0.x releases of TBMQ, focusing on how these changes optimize persistent session handling, enhance P2P messaging, and improve overall system efficiency within a scalable IoT architecture.
We hope this article offers valuable insights for software engineers looking for ideas and patterns to offload database workloads to persistent caching layers, helping to improve scalability and performance in their systems. Additionally, for those exploring a Mosquitto alternative, TBMQ stands out as a powerful and fault-tolerant MQTT broker option.
Fan-in Pattern
While the TBMQ 1.x version can handle 100 million clients at once and dispatches 3 million messages per second, as a high-performance MQTT broker it was primarily designed to aggregate data from IoT devices and deliver it to back-end applications reliably (QoS 1). This architecture is based on our experience with IIoT and other large-scale IoT deployments, where millions of devices transmit data to a limited number of applications.
Through these deployments, we recognized that IoT devices and applications follow distinct communication patterns. IoT devices or sensors publish data frequently but subscribe to relatively few topics or updates. In contrast, applications subscribe to data from tens or even hundreds of thousands of devices and require reliable message delivery. Additionally, applications often experience periods of downtime due to system maintenance, upgrades, failover scenarios, or temporary network disruptions.
To address these differences, TBMQ introduces a key feature: the classification of MQTT clients as either standard (IoT devices) or application clients. This distinction enables optimized handling of persistent MQTT sessions for applications. Specifically, each persistent application client is assigned a separate Kafka topic. This approach ensures efficient message persistence and retrieval when an MQTT client reconnects, improving overall reliability and performance. Additionally, application clients support MQTT’s shared subscription feature, allowing multiple instances of an application to efficiently distribute message processing.



Kafka serves as one of the core components. Designed for high-throughput, distributed messaging, Kafka efficiently handles large volumes of data streams, making it an ideal choice for TBMQ. With the latest Kafka versions capable of managing a huge number of topics, this architecture is well-suited for enterprise-scale deployments.
P2P Pattern
Unlike the fan-in, the point-to-point (P2P) communication pattern enables direct message exchange between MQTT clients. Typically implemented using uniquely defined topics, P2P is well-suited for private messaging, device-to-device communication, command transmission, and other direct interaction use cases.
One of the key differences between fan-in and peer-to-peer MQTT messaging is the volume and flow of messages. In a P2P scenario, subscribers do not handle high message volumes, making it unnecessary to allocate dedicated Kafka topics and consumer threads to each MQTT client. Instead, the primary requirements for P2P message exchange are low latency and reliable message delivery, even for clients that may go offline temporarily. To meet these needs, TBMQ optimizes persistent session management for standard MQTT clients, which include IoT devices.

In TBMQ 1.x, standard MQTT clients relied on PostgreSQL for message persistence and retrieval, ensuring that messages were delivered when a client reconnected. While PostgreSQL performed well initially, it had a fundamental limitation—it could only scale vertically. We anticipated that as the number of persistent MQTT sessions grew, PostgreSQL’s architecture would eventually become a bottleneck. To address this, we explored more scalable alternatives capable of handling the increasing demands of our MQTT broker. Redis was quickly chosen as the best fit due to its horizontal scalability, native clustering support, and widespread adoption.
PostgreSQL usage and limitations
To fully understand the reasoning behind this shift, it’s important to first examine how MQTT clients operated within the PostgreSQL architecture. This architecture was built around two key tables.
The device_session_ctx table was responsible for maintaining the session state of each persistent MQTT client:
Table "public.device_session_ctx"
Column | Type | Collation | Nullable | Default
--------------------+------------------------+-----------+----------+---------
client_id | character varying(255) | | not null |
last_updated_time | bigint | | not null |
last_serial_number | bigint | | |
last_packet_id | integer | | |
Indexes:
"device_session_ctx_pkey" PRIMARY KEY, btree (client_id)The key columns are last_packet_id and last_serial_number, which is used to maintain message order for persistent MQTT clients:
-
last_packet_idrepresents the packet ID of the last MQTT message received. -
last_serial_numberacts as a continuously increasing counter, preventing message order issues when the MQTT packet ID wraps around after reaching its limit of65535.
The device_publish_msg table was responsible for storing messages that must be published to persistent MQTT clients (subscribers).
Table "public.device_publish_msg"
Column | Type | Collation | Nullable | Default
--------------------------+------------------------+-----------+----------+---------
client_id | character varying(255) | | not null |
serial_number | bigint | | not null |
topic | character varying | | not null |
time | bigint | | not null |
packet_id | integer | | |
packet_type | character varying(255) | | |
qos | integer | | not null |
payload | bytea | | not null |
user_properties | character varying | | |
retain | boolean | | |
msg_expiry_interval | integer | | |
payload_format_indicator | integer | | |
content_type | character varying(255) | | |
response_topic | character varying(255) | | |
correlation_data | bytea | | |
Indexes:
"device_publish_msg_pkey" PRIMARY KEY, btree (client_id, serial_number)
"idx_device_publish_msg_packet_id" btree (client_id, packet_id)The key columns to highlight:
-
time– captures the system time (timestamp) when the message is stored. This field is used for periodic cleanup of expired messages. -
msg_expiry_interval– represents the expiration time (in seconds) for a message. This is set only for incoming MQTT 5 messages that include an expiry property. If the expiry property is absent, the message does not have a specific expiration time and remains valid until it is removed by time or size-based cleanup.
Together, these tables manage message persistence and session state. The device_session_ctx table is designed for fast retrieval of the last MQTT packet ID and serial number stored for each persistent MQTT client. When messages for a client are received from a shared Kafka topic, the broker queries this table to fetch the latest values. These values are incremented sequentially and assigned to each message before being saved to the device_publish_msg table.
While this design ensured reliable message delivery, it also introduced performance constraints. To better understand its limitations, we conducted prototype testing to evaluate PostgreSQL’s performance under the P2P communication pattern. Using a single instance with 64GB RAM and 12 CPU cores, we simulated message loads with a dedicated performance testing tool capable of generating MQTT clients and simulating the desired message load. The primary performance metric was the average message processing latency — measured from the moment the message was published to the point it was acknowledged by the subscriber. The test was considered successful only if there was no performance degradation, meaning the broker consistently maintained an average latency in the two-digit millisecond range.
With the prototype testing, we ultimately reach the limit at 30k msg/s throughput utilizing PostgreSQL as a persistence message storage. Throughput refers to the total number of messages per second, including both incoming and outgoing messages.
Based on the TimescaleDB blog post, vanilla PostgreSQL can handle up to 300k inserts per second under ideal conditions. However, this performance depends on factors such as hardware, workload, and table schema. While vertical scaling can provide some improvement, PostgreSQL’s per-table insert throughput eventually reaches a hard limit. Confident that Redis could overcome this bottleneck, we began the migration process to achieve greater scalability and efficiency.
Redis as a scalable alternative
Our decision to migrate to Redis was driven by its ability to address the core performance bottlenecks encountered with PostgreSQL. Unlike PostgreSQL, which relies on disk-based storage and vertical scaling, Redis operates primarily in memory, significantly reducing read and write latency. Additionally, Redis’s distributed architecture enables horizontal scaling, making it an ideal fit for high-throughput messaging in P2P communication scenarios.

With these benefits in mind, we started our migration process with an evaluation of data structures that could preserve the functionality of the PostgreSQL approach while aligning with Redis Cluster constraints to enable efficient horizontal scaling. This also presented an opportunity to improve certain aspects of the original design, such as periodic cleanups, by leveraging Redis features like built-in expiration mechanisms.
Redis Cluster Constraints
When migrating from PostgreSQL to Redis, we recognized that replicating the existing data model would require multiple Redis data structures to efficiently handle message persistence and ordering. This, in turn, meant using multiple keys for each persistent MQTT Client session.
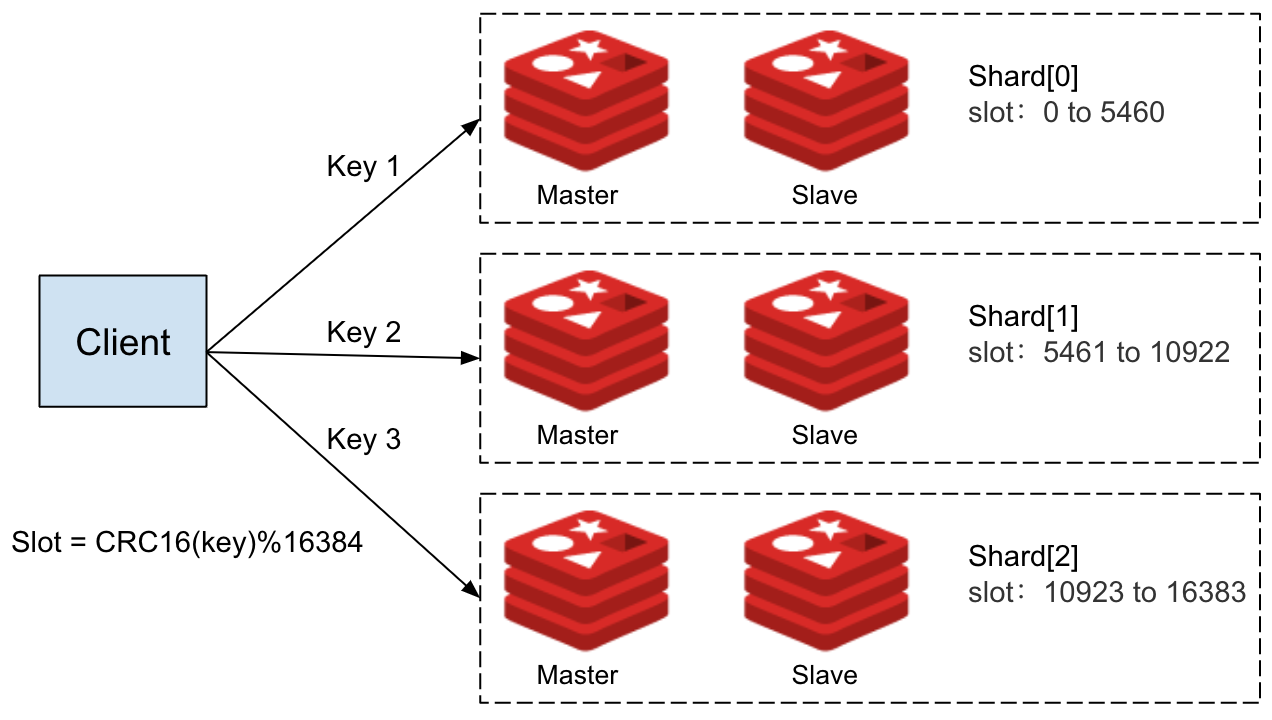
Redis Cluster distributes data across multiple slots to enable horizontal scaling. However, multi-key operations must access keys within the same slot. If the keys reside in different slots, the operation triggers a cross-slot error, preventing the command from executing. We used the persistent MQTT client ID as a hash tag in our key names to address this. By enclosing the client ID in curly braces {}, Redis ensures that all keys for the same client are hashed to the same slot. This guarantees that related data for each client stays together, allowing multi-key operations to proceed without errors.
Atomic operations via Lua scripts
Consistency is critical in a high-throughput environment like TBMQ, where many messages can arrive simultaneously for the same MQTT client. Hashtagging helps to avoid cross-slot errors, but without atomic operations, there is a risk of race conditions or partial updates. This could lead to message loss or incorrect ordering. It is important to make sure that operations updating the keys for the same MQTT client are atomic.

Redis is designed to execute individual commands atomically. However, in our case, we need to update multiple data structures as part of a single operation for each MQTT client. Executing these sequentially without atomicity opens the door to inconsistencies if another process modifies the same data in between commands. That’s where Lua scripting comes in. Lua script executes as a single, isolated unit. During script execution, no other commands can run concurrently, ensuring that the operations inside the script happen atomically.
Based on this information, we decided that for any operation, such as saving messages or retrieving undelivered messages upon reconnection, we will execute a separate Lua script. This ensures that all operations within a single Lua script reside in the same hash slot, maintaining atomicity and consistency.
Choosing the right Redis data structures
One of the key requirements of the migration was maintaining message order, a task previously handled by the serial_number column in PostgreSQL’s device_publish_msg table. After evaluating various Redis data structures, we determined that sorted sets (ZSETs) were the ideal replacement.
Redis sorted sets naturally organize data by score, enabling quick retrieval of messages in ascending or descending order. While sorted sets provided an efficient way to maintain message order, storing full message payloads directly in sorted sets led to excessive memory usage. Redis does not support per-member TTL within sorted sets. As a result, messages persisted indefinitely unless explicitly removed. Similar to PostgreSQL, we had to perform periodic cleanups using ZREMRANGEBYSCORE to delete expired messages. This operation carries a complexity of O(log N + M), where M is the number of elements removed. To overcome this limitation we decided to store message payloads using strings data structure while storing in the sorted set references to these keys.
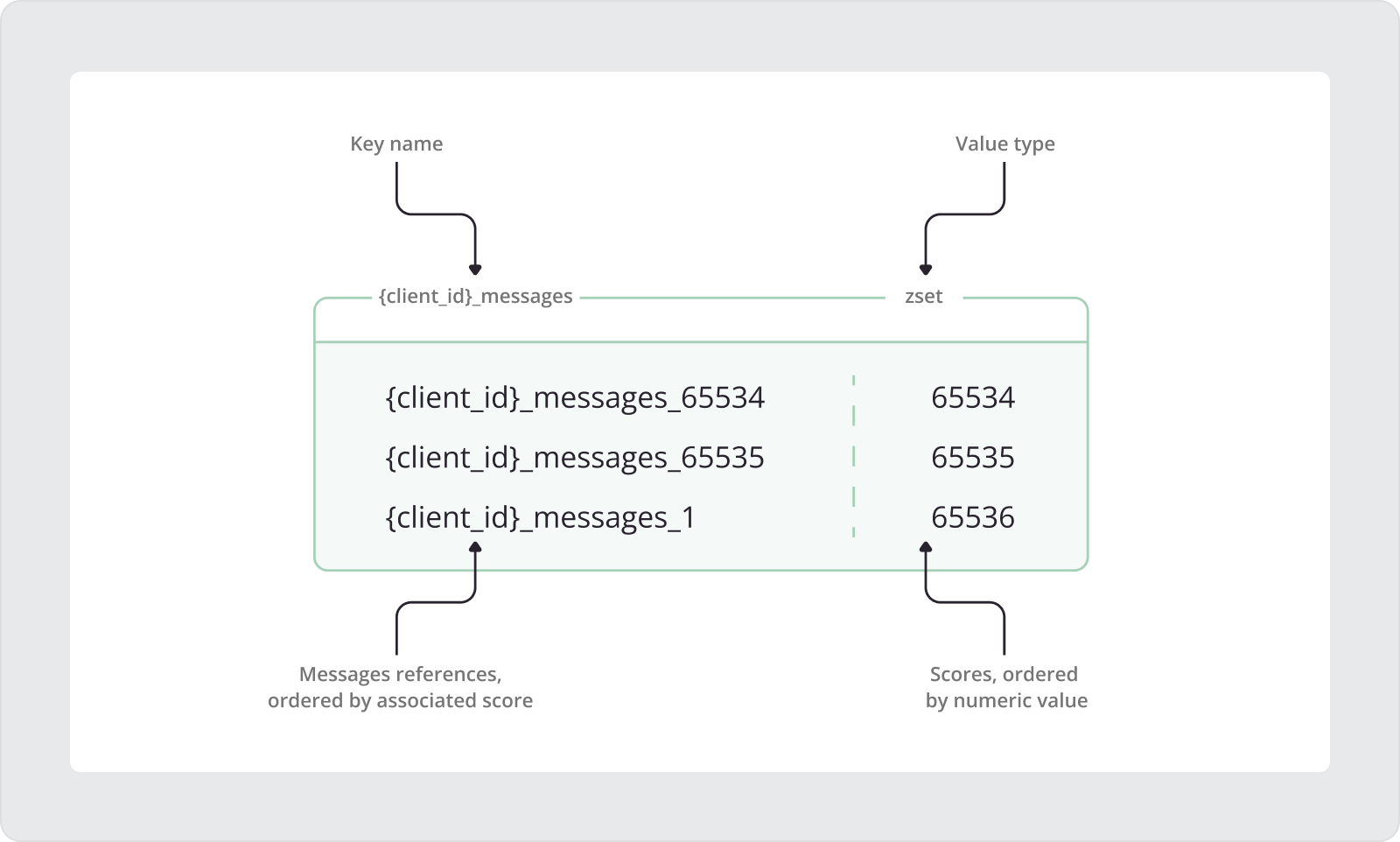
client_id is a placeholder for the actual client ID, while the curly braces {} around it are added to create a hash tag.In the image above, you can see that the score continues to grow even when the MQTT packet ID wraps around. Let’s take a closer look at the details illustrated in this image. At first, the reference for the message with the MQTT packet ID equal to 65534 was added to the sorted set:
ZADD {client_id}_messages 65534 {client_id}_messages_65534Here, {client_id}_messages is the sorted set key name, where {client_id} acts as a hash tag derived from the persistent MQTT client’s unique ID. The suffix _messages is a constant added to each sorted set key name for consistency. Following the sorted set key name, the score value 65534 corresponds to the MQTT packet ID of the message received by the client. Finally, we see the reference key that points to the actual payload of the MQTT message. Similar to the sorted set key, the message reference key uses the MQTT client’s ID as a hash tag, followed by the _messages suffix and the MQTT packet ID value.
In the next iteration, we add the message reference for the MQTT message with a packet ID equal to 65535 into the sorted set. This is the maximum packet ID, as the range is limited to 65535.
ZADD {client_id}_messages 65535 {client_id}_messages_65535So at the next iteration MQTT packet ID should be equal to 1, while the score should continue to grow and be equal to 65536.
ZADD {client_id}_messages 65536 {client_id}_messages_1This approach ensures that the message’s references will be properly ordered in the sorted set regardless of the packet ID’s limited range.
Message payloads are stored as string values with SET commands that support expiration (EX), providing O(1) complexity for writes and TTL applications:
SET {client_id}_messages_1 "{
\"packetType\":\"PUBLISH\",
\"payload\":\"eyJkYXRhIjoidGJtcWlzYXdlc29tZSJ9\",
\"time\":1736333110026,
\"clientId\":\"client\",
\"retained\":false,
\"packetId\":1,
\"topicName\":\"europe/ua/kyiv/client/0\",
\"qos\":1
}" EX 600Another benefit aside from efficient updates and TTL applications is that the message payloads can be retrieved:
GET {client_id}_messages_1or removed:
DEL {client_id}_messages_1with constant complexity O(1) without affecting the sorted set structure.
Another very important element of our Redis architecture is the use of a string key to store the last MQTT packet ID processed:
GET {client_id}_last_packet_id
"1"This approach serves the same purpose as in the PostgreSQL solution. When a client reconnects, the server must determine the correct packet ID to assign to the next message that will be saved in Redis. Initially, we considered using the sorted set’s highest score as a reference. However, since there are scenarios where the sorted set could be empty or completely removed, we concluded that the most reliable solution is to store the last packet ID separately.
Managing Sorted Set Size Dynamically
This hybrid approach, leveraging sorted sets and string data structures, eliminates the need for periodic cleanups based on time, as per-message TTLs are now applied. In addition, following the PostgreSQL design we needed to address somehow the cleanup of the sorted set based on the messages limit set in the configuration.
# Maximum number of PUBLISH messages stored for each persisted DEVICE client
limit: "${MQTT_PERSISTENT_SESSION_DEVICE_PERSISTED_MESSAGES_LIMIT:10000}"This limit is an important part of our design, allowing us to control and predict the memory allocation required for each persistent MQTT client. For example, a client might connect, triggering the registration of a persistent session, and then rapidly disconnect. In such scenarios, it is essential to ensure that the number of messages stored for the client (while waiting for a potential reconnection) remains within the defined limit, preventing unbounded memory usage.
if (messagesLimit > 0xffff) {
throw new IllegalArgumentException("Persisted messages limit can't be greater than 65535!");
}To reflect the natural constraints of the MQTT protocol, the maximum number of persisted messages for individual clients is set to 65535.
To handle this within the Redis solution, we implemented dynamic management of the sorted set’s size. When new messages are added, the sorted set is trimmed to ensure the total number of messages remains within the desired limit, and the associated strings are also cleaned up to free up memory.
-- Get the number of elements to be removed
local numElementsToRemove = redis.call('ZCARD', messagesKey) - maxMessagesSize
-- Check if trimming is needed
if numElementsToRemove > 0 then
-- Get the elements to be removed (oldest ones)
local trimmedElements = redis.call('ZRANGE', messagesKey, 0, numElementsToRemove - 1)
-- Iterate over the elements and remove them
for _, key in ipairs(trimmedElements) do
-- Remove the message from the string data structure
redis.call('DEL', key)
-- Remove the message reference from the sorted set
redis.call('ZREM', messagesKey, key)
end
end
Message Retrieval and Cleanup
Our design not only ensures dynamic size management during the persistence of new messages but also supports cleanup during message retrieval, which occurs when a device reconnects to process undelivered messages. This approach keeps the sorted set clean by removing references to expired messages.
-- Define the sorted set key
local messagesKey = KEYS[1]
-- Define the maximum allowed number of messages
local maxMessagesSize = tonumber(ARGV[1])
-- Get all elements from the sorted set
local elements = redis.call('ZRANGE', messagesKey, 0, -1)
-- Initialize a table to store retrieved messages
local messages = {}
-- Iterate over each element in the sorted set
for _, key in ipairs(elements) do
-- Check if the message key still exists in Redis
if redis.call('EXISTS', key) == 1 then
-- Retrieve the message value from Redis
local msgJson = redis.call('GET', key)
-- Store the retrieved message in the result table
table.insert(messages, msgJson)
else
-- Remove the reference from the sorted set if the key does not exist
redis.call('ZREM', messagesKey, key)
end
end
-- Return the retrieved messages
return messagesBy leveraging Redis’ sorted sets and strings, along with Lua scripting for atomic operations, our new design achieves efficient message persistence and retrieval, as well as dynamic cleanup. This design addresses the scalability limitations of the PostgreSQL-based solution.
In the next sections, we describe the performance of the new Redis-based architecture compared to the PostgreSQL solution. These sections present the results of the performance tests and their key findings.
Migration from Jedis to Lettuce

As we mentioned earlier, we conducted a prototype test that revealed the limit of 30k msg/s throughput when using PostgreSQL for persistence message storage. At the moment we migrated to Redis, we already used the Jedis library for Redis interactions, primarily for cache management, and extended it to handle message persistence for persistent MQTT clients. However, the initial results of the Redis implementation with Jedis were unexpected. While we anticipated Redis would significantly outperform PostgreSQL, the performance improvement was modest – reaching only 40k msg/s throughput compared to the 30k msg/s limit with PostgreSQL.
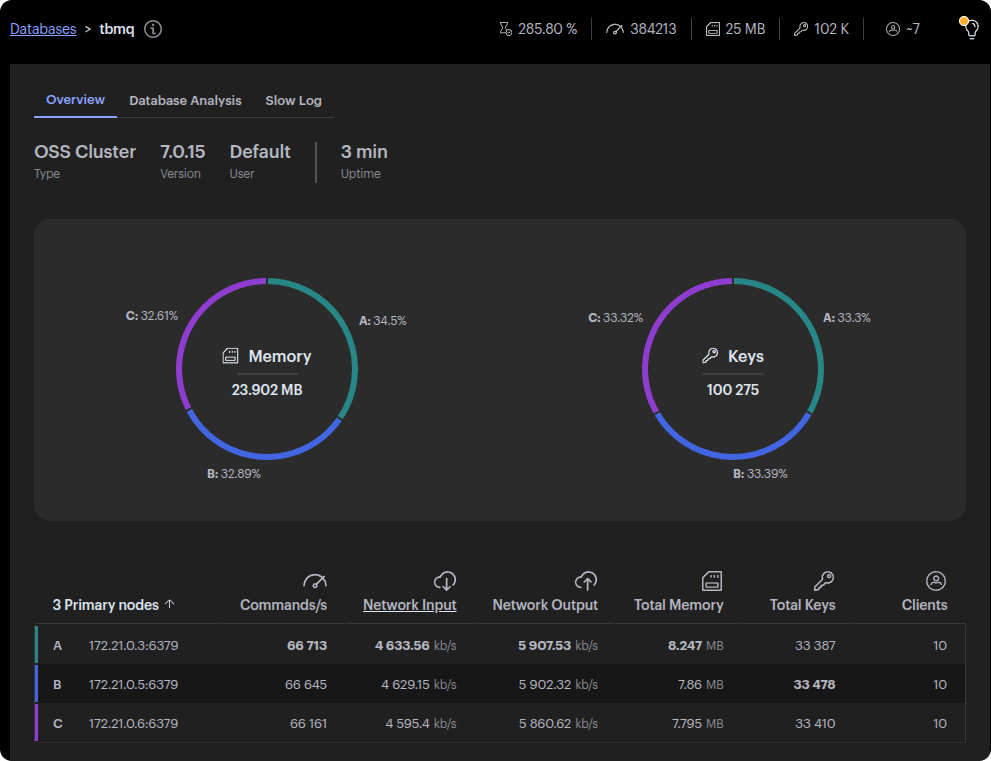
This led us to investigate the bottlenecks, where we discovered that Jedis was a limiting factor. While reliable, Jedis operates synchronously, processing each Redis command sequentially. This forces the system to wait for one operation to complete before executing the next. In high-throughput environments, this approach significantly limited Redis’s potential, preventing the full utilization of system resources.
To overcome this limitation, we migrated to Lettuce, an asynchronous Redis client built on top of Netty. With Lettuce, our throughput increased to 60k msg/s, demonstrating the benefits of non-blocking operations and improved parallelism.
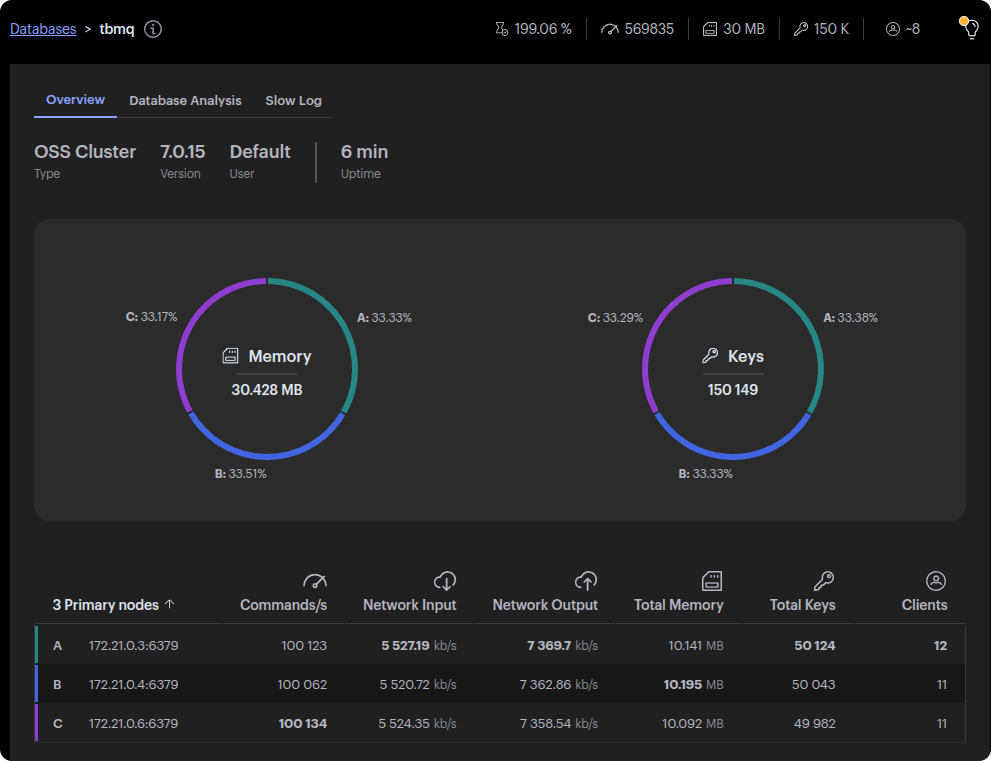
Lettuce allows multiple commands to be sent and processed in parallel, fully exploiting Redis’s capacity for concurrent workloads. Ultimately, the migration unlocked the performance gains we expected from Redis, paving the way for successful P2P testing at scale.
Scaling Point-to-point Messaging
With Redis and Lettuce fully integrated, the next challenge was ensuring TBMQ’s ability to handle large-scale P2P messaging in a distributed environment. To simulate real-world conditions, we deployed TBMQ on AWS EKS (Elastic Kubernetes Service), allowing us to dynamically scale and stress-test the system.
To evaluate performance and prove that our system can scale efficiently, we started with 200,000 messages per second and increased the load by 200,000 messages in each iteration. In each phase, we scaled the number of TBMQ brokers and Redis nodes to handle the growing traffic while keeping the system stable. For the 1M msg/sec test, we also scaled the number of Kafka brokers to handle the corresponding workload.
| Throughput (msg/sec) | Publishers | Subscribers | TBMQ brokers | Redis Nodes | Kafka brokers |
| 200k | 100k | 100k | 1 | 3 | 3 |
| 400k | 200k | 200k | 2 | 5 | 3 |
| 600k | 300k | 300k | 3 | 7 | 3 |
| 800k | 400k | 400k | 4 | 9 | 3 |
| 1M | 500k | 500k | 5 | 11 | 5 |
Beyond adding resources, each increase in load required fine-tuning of Kafka topic partitioning and Lettuce command batching parameters. These adjustments helped distribute traffic evenly and keep latency stable, preventing bottlenecks as we scaled.
| Throughput (msg/sec) | Kafka topic partitions | Lettuce batch size |
| 200k | 12 | 150 |
| 400k | 12 | 250 |
| 600k | 12 | 300 |
| 800k | 16 | 400 |
| 1M | 20 | 500 |
Lettuce batch size – Number of Redis commands buffered before a flush. Commands are flushed either when the batch size is reached or every 3 ms, whichever comes first.
We reached our target of 1 million messages per second, validating TBMQ’s capability to support high-throughput reliable P2P messaging. To better illustrate the test setup and results, the following diagram provides a visual breakdown of the final performance test.

Tests results
Throughout testing, we monitored key performance indicators such as CPU utilization, memory usage, and message processing latency. One of TBMQ’s standout advantages, highlighted in our P2P testing, is its exceptional messages-per-second per CPU core performance. Compared to public benchmarks of other brokers, TBMQ consistently delivers higher throughput with fewer resources, reinforcing its efficiency in large-scale deployments.
Key takeaways from tests include:
- Scalability: TBMQ demonstrated linear scalability. By incrementally adding TBMQ nodes, Redis nodes, and Kafka nodes at higher workloads, we maintained reliable performance as the message throughput increased from 200k to 1M msg/sec.
- Efficient Resource Utilization: CPU utilization on TBMQ nodes remained consistently around ~90% across all test phases, indicating that the system effectively used available resources without overconsumption.
- Latency Management: The observed latency across all tests remained within two-digit bounds. This was predictable given the QoS 1 level chosen for our test, applied to both publishers and persistent subscribers. We also tracked the average acknowledgment latency for publishers, which stayed within single-digit bounds across all test phases.
- High Performance: TBMQ’s one-to-one communication pattern showed excellent efficiency, processing about 8900 msg/s per CPU core. We calculated this by dividing the total throughput by the total number of CPU cores used in the setup.
Additionally, the following table provide a comprehensive summary of the key elements and results of the final 1M msg/sec test:
| QoS | P2P latency |
Publish latency |
Messages per second per CPU core |
TBMQ CPU usage |
Payload (bytes) |
| 1 | ~75ms | ~8ms | 8900 | 91% | 62 |
P2P latency: The average duration from when a PUB message is sent by the publisher to when it is received by the subscriber.
Publish latency: The average time elapsed between the PUB message sent by the publisher and the reception of the PUBACK acknowledgment.
For a deeper dive into the testing architecture, methodology, and results, check out our detailed performance testing article.
Conclusion
TBMQ 2.x sets a new benchmark for self-hosted MQTT brokers, proving its ability to handle one million messages per second for persistent sessions without data loss—even in the event of hardware failures. Designed to eliminate single points of failure and bottlenecks, TBMQ achieves exceptional efficiency through a combination of Redis for persistence, Kafka for message distribution, and a highly optimized broker codebase.
In our tests and by comparing public data from other platforms, TBMQ leads in messages processed per CPU core (~8,900 msg/sec), making it a strong choice for high-throughput IIoT and other MQTT deployments. This efficiency is not just a raw metric—it also means lower infrastructure costs and simpler scaling.
TBMQ has long been a top performer in fan-in and fan-out scenarios, handling data from millions of devices to back-end systems with ease. Now, it also stands out in P2P messaging, offering low latency and high throughput for one-to-one communication use cases. If you need massive throughput, low latency, and efficient resource usage, TBMQ offers a proven path forward.