3M msg/sec throughput with a single TBMQ node
In the context of MQTT brokers, optimal performance under high workloads is critical. This article explores a performance test of TBMQ demonstrating its ability to handle 3 million messages per second with single-digit millisecond latency — using a single node.
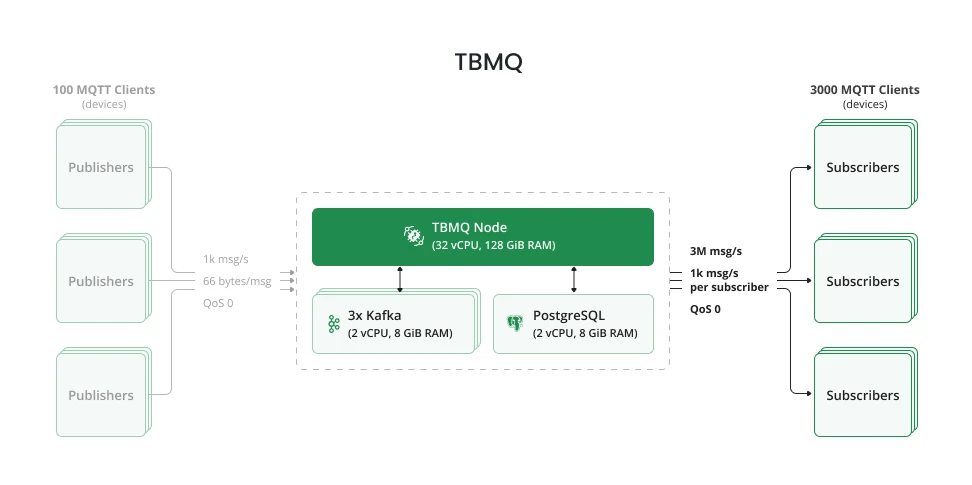
Test methodology
Section titled “Test methodology”A single TBMQ node was deployed within an EKS cluster alongside 3 Kafka nodes and an RDS instance.
Publishers: 100 clients, each publishing 10 msg/sec to their own topic following the pattern
CountryCode/City/ID. Message size: ~66 bytes.
Subscribers: 3,000 clients, each subscribing to CountryCode/City/# to receive all messages from all
publishers. With 100 publishers × 10 msg/sec × 3,000 subscribers = 3M messages per second total throughput.
The test ran for 30 minutes to verify TBMQ can sustain this load without performance degradation or resource exhaustion.
Hardware used
Section titled “Hardware used”| Service | TBMQ | AWS RDS (PostgreSQL) | Kafka |
|---|---|---|---|
| Instance type | m7a.8xlarge | db.m6i.large | m7a.large |
| vCPU | 32 | 2 | 2 |
| Memory (GiB) | 128 | 8 | 8 |
| Storage (GiB) | 10 | 30 | 50 |
| Network (Gbps) | 12.5 | 12.5 | 12.5 |
Test summary
Section titled “Test summary”| Publishers | Subscribers | Msg/sec/publisher | Total throughput | QoS | Payload | TBMQ CPU | TBMQ memory |
|---|---|---|---|---|---|---|---|
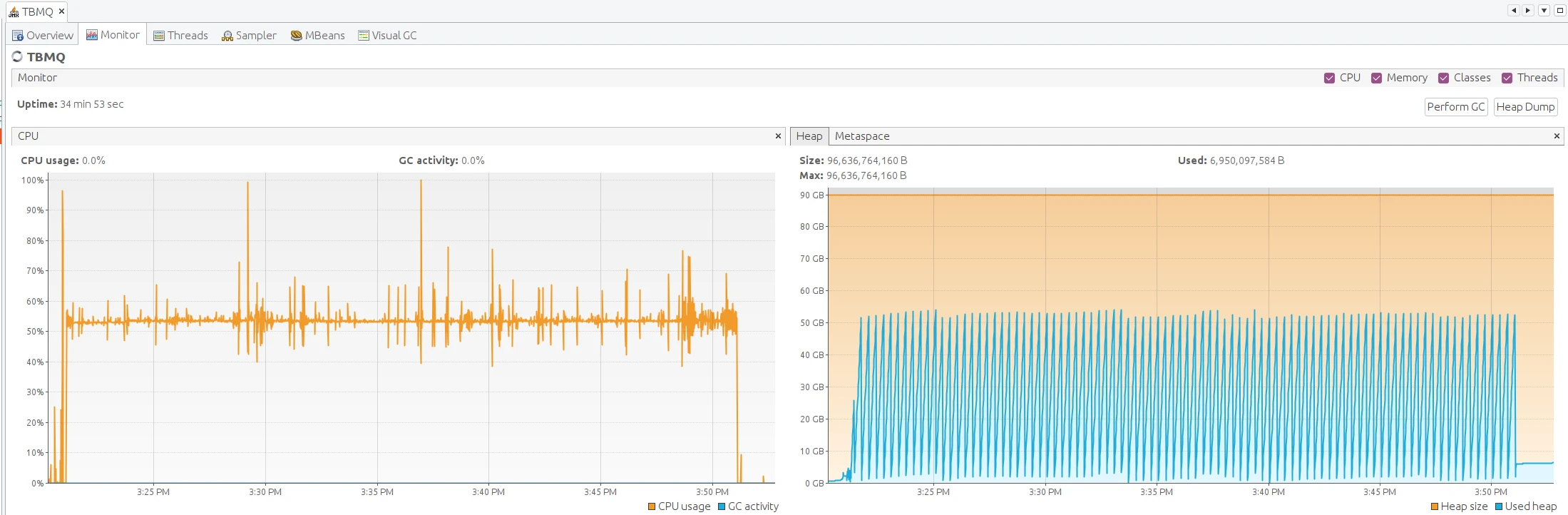
| 100 | 3,000 | 10 | 3M msg/s | 0 | 66 bytes | 54% | 75 GiB |
Latency:
| Msg latency avg | Msg latency 95th |
|---|---|
| 7.4 ms | 11 ms |
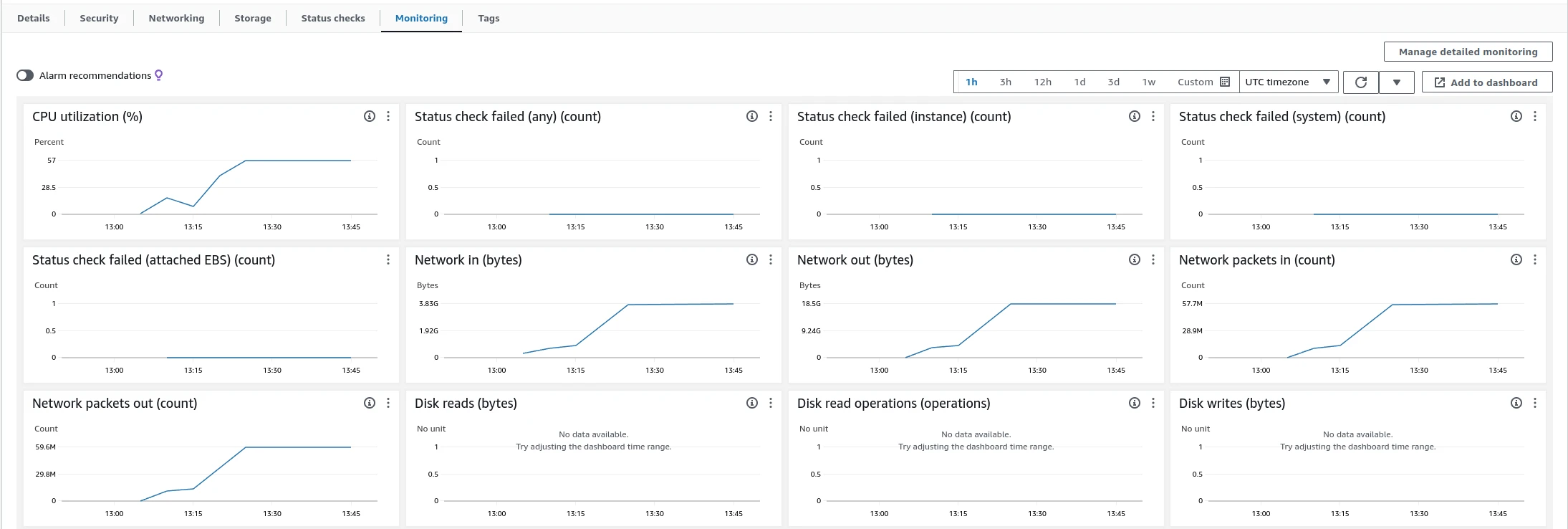
At 54% CPU utilization, TBMQ demonstrates substantial remaining processing capacity, suggesting it can efficiently handle even higher workloads and message delivery peaks.
Alternative instance: tests on m7a.4xlarge (16 vCPU, 64 GiB) achieved 14.2 ms average latency at
90% CPU, highlighting TBMQ’s flexibility across different instance types.
Running the test
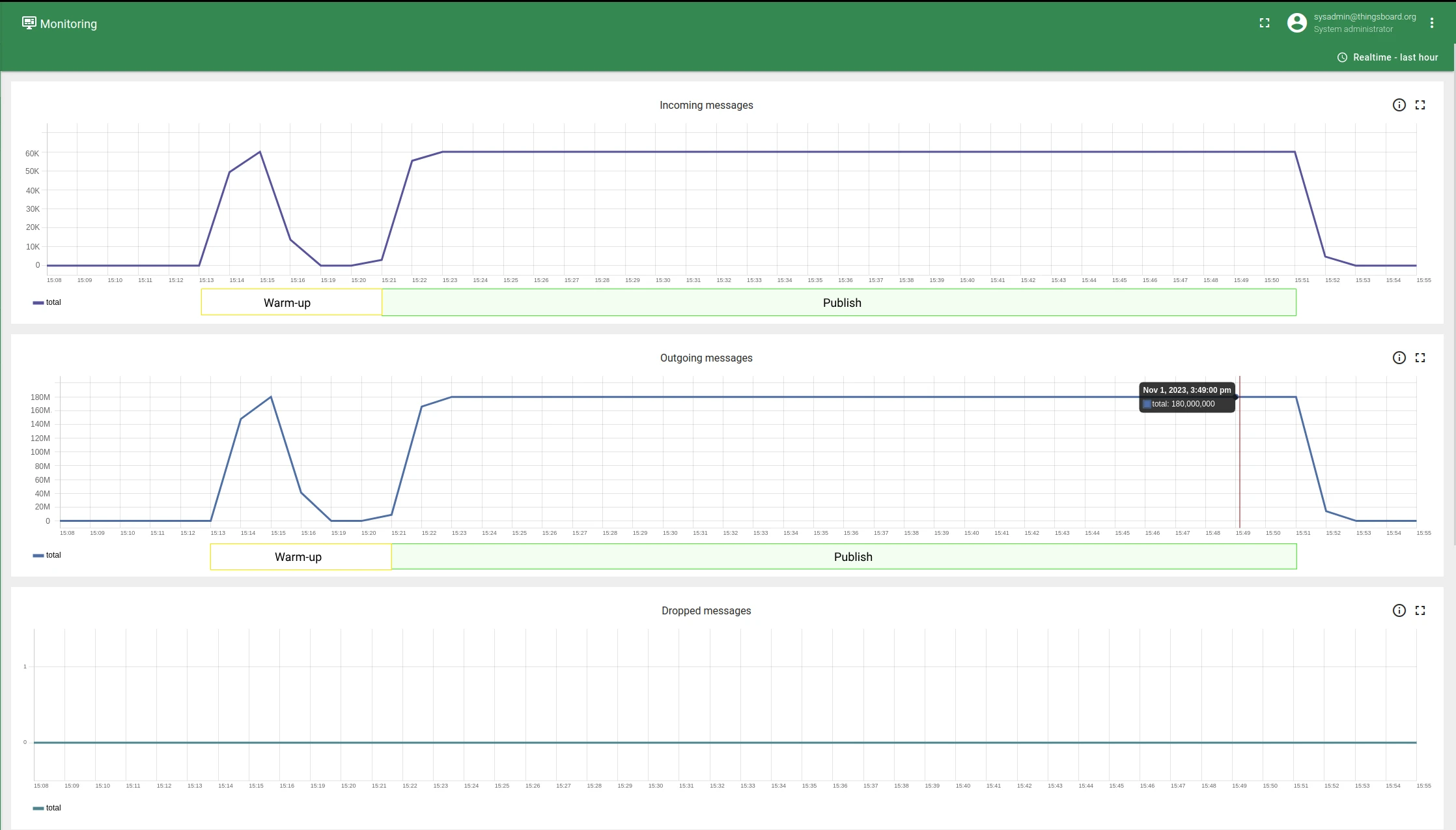
Section titled “Running the test”The test agent is a cluster of performance test nodes (runners) supervised by an orchestrator. For this test, the agent consisted of 1 publisher pod, 6 subscriber pods, and 1 orchestrator pod — each on a separate AWS EC2 instance.
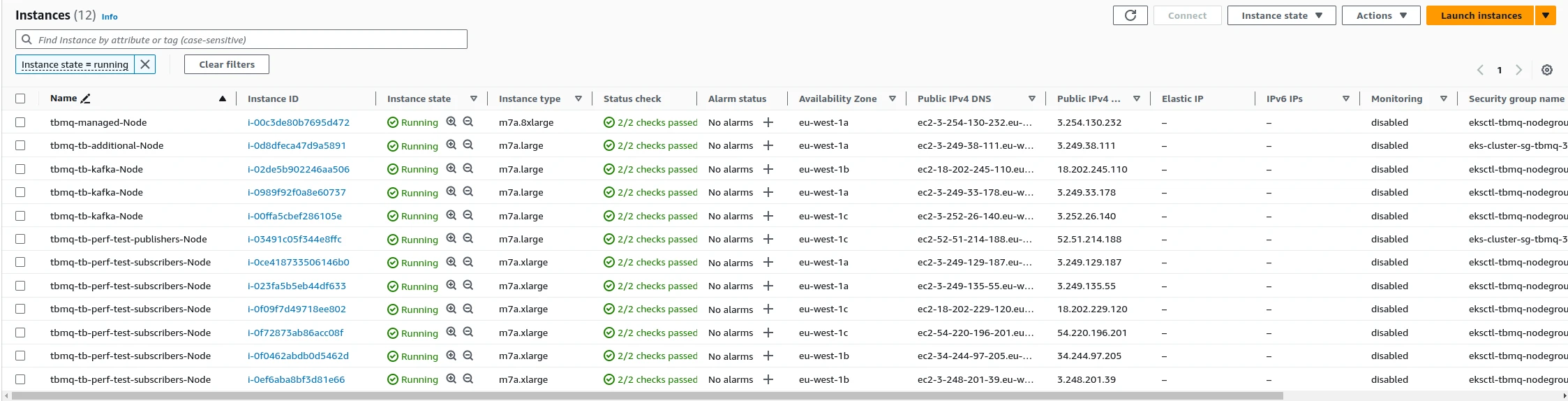
Subscriber clients set up their subscriptions; publishers ran a warm-up phase. Once all runners reported ready to the orchestrator, message publishing began. Monitoring was performed using JMX, htop, Kafka UI, and AWS CloudWatch.
How to repeat the test
Section titled “How to repeat the test”Refer to the AWS cluster installation guide for deployment instructions.
- TBMQ branch with test scripts
- Performance testing tool
- Publisher configuration
- Subscriber configuration
Conclusion
Section titled “Conclusion”TBMQ successfully processed 3M messages per second with an average latency of 7.4 ms on a single node, confirming its position as a scalable MQTT broker ready for demanding fan-out workloads. Follow the project on GitHub for further performance results.
Was this helpful?