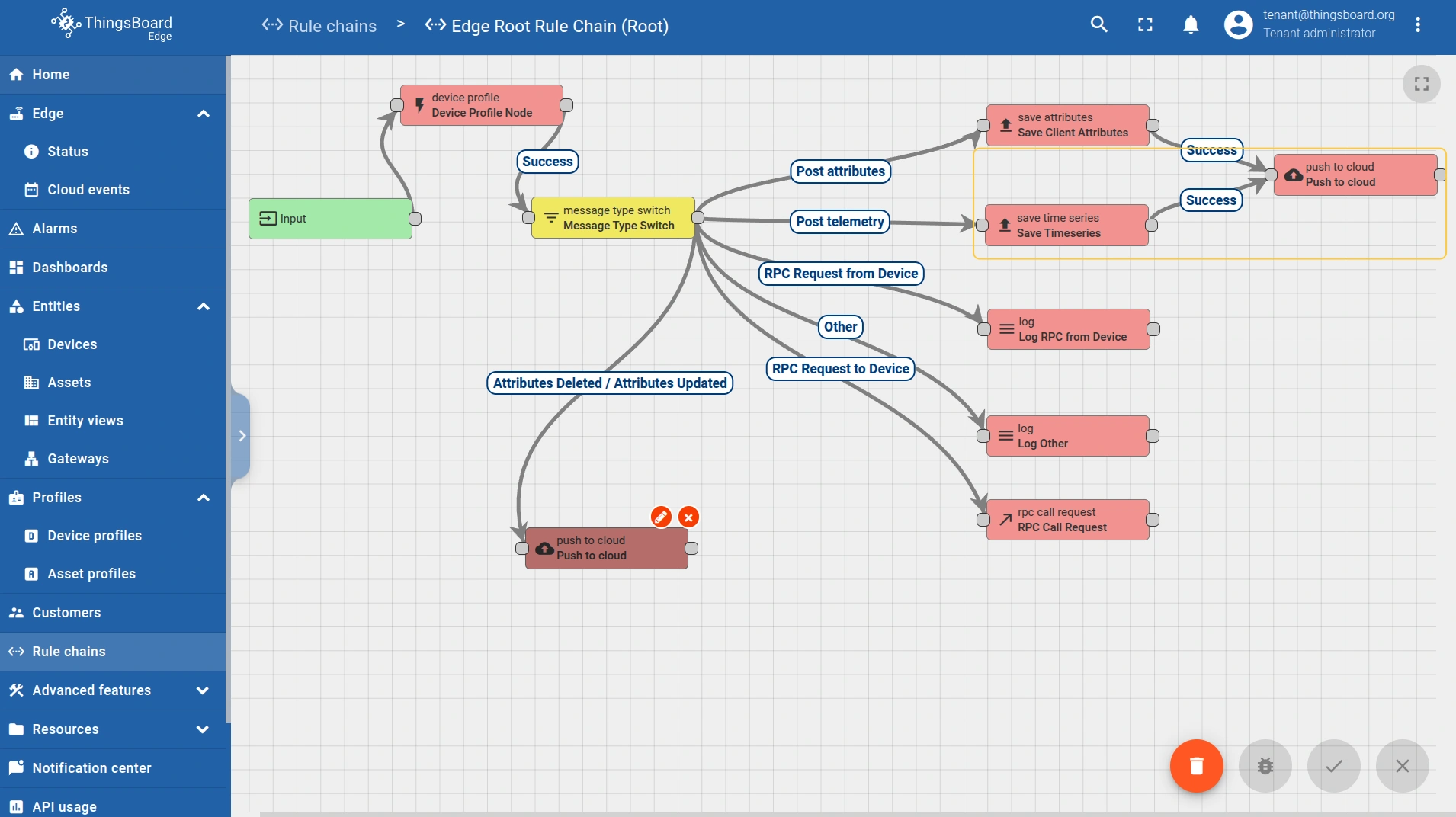
ThingsBoard Edge does not automatically sync telemetry data. Instead, it’s a rule-based process. The “push to cloud” and “push to edge” rule nodes are responsible for the synchronization process.
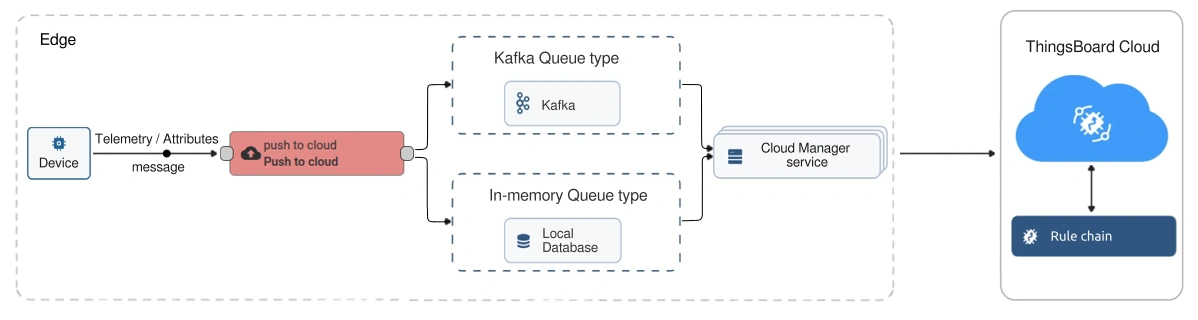
Edge → Cloud sync
Edge synchronizes data (timeseries, attributes, etc.) through the “push to cloud” rule node within an Edge rule chain. When a telemetry or attribute message passes through this rule node, it’s first stored locally on the Edge as a Cloud Event in either a local database or Kafka (depending on the queue type). The event is then asynchronously pushed to the Cloud. This means the Edge device doesn’t wait for a Cloud delivery confirmation before continuing with other tasks. Once it reaches the Cloud, it is handled by a corresponding rule chain on the Cloud.
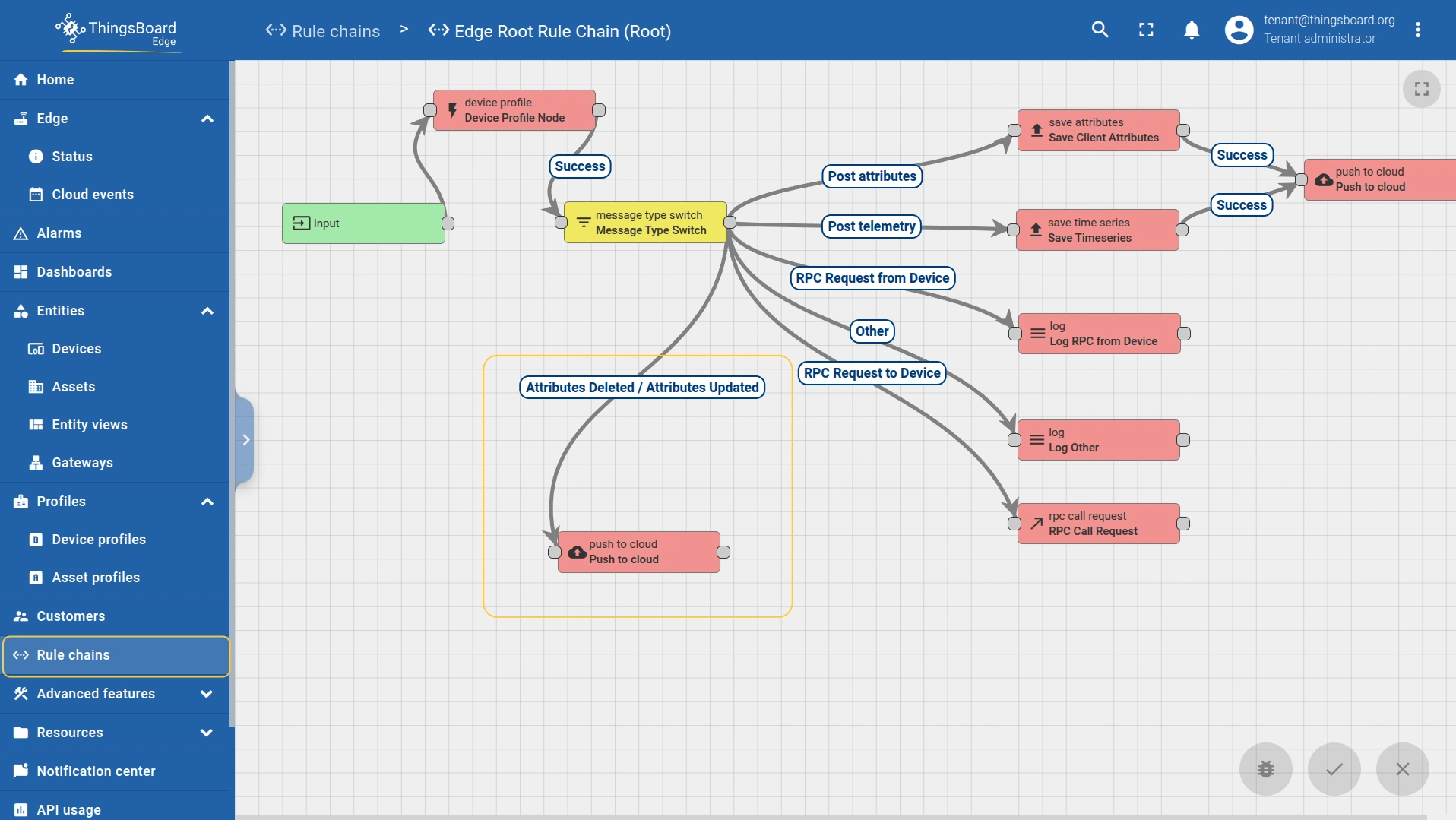
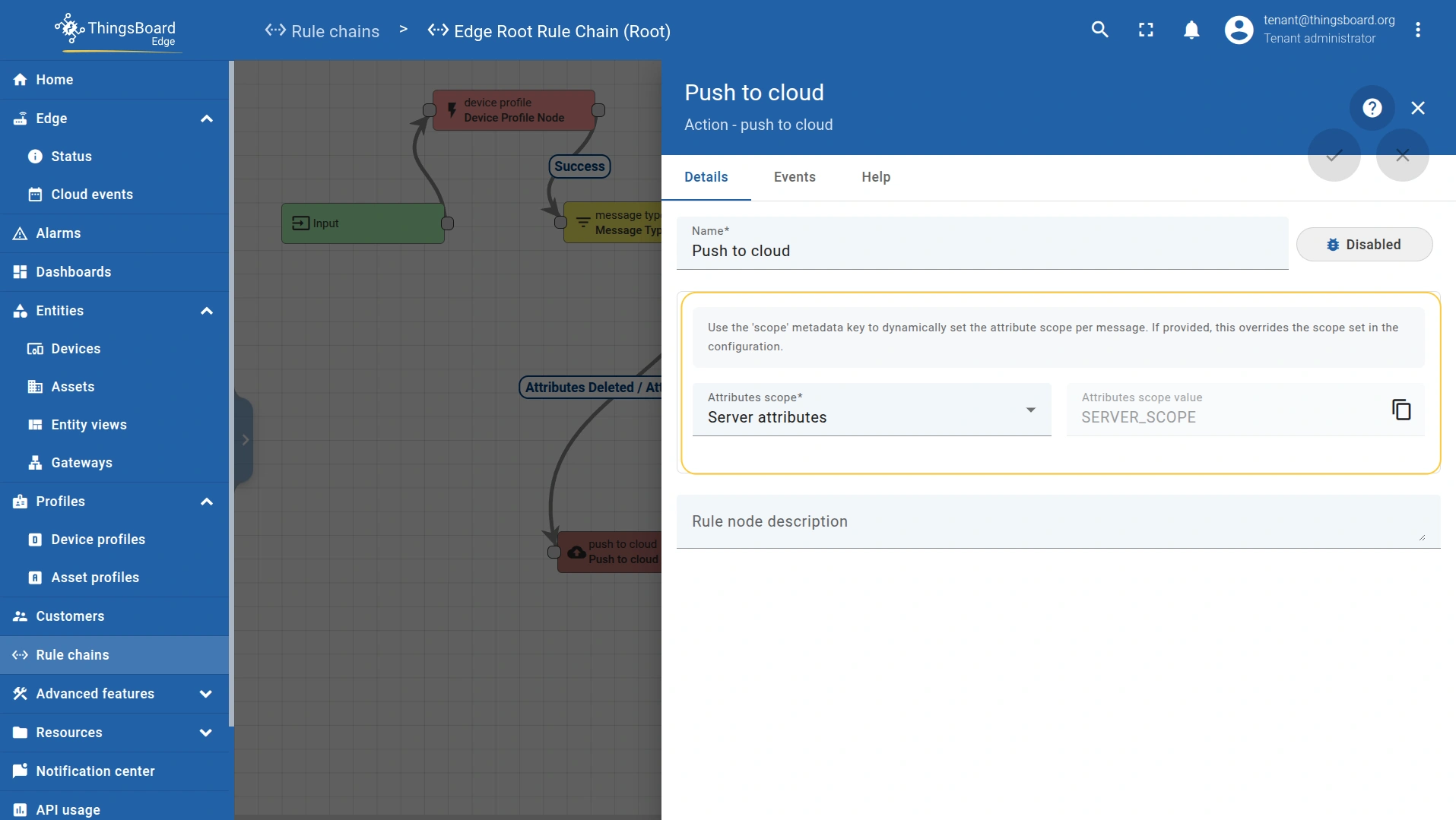
- To propagate attribute changes, connect the Attributes updated and Attributes deleted relations to the “push to cloud” node. This ensures both the key–values and the scope travel with the event.
- The attribute scope type (Server attributes, Shared attributes, or Client attributes) is also configured within the “push to cloud” node.
Data storage on the Cloud
The database tables updated in Cloud depend entirely on your Cloud‑side rule chain.
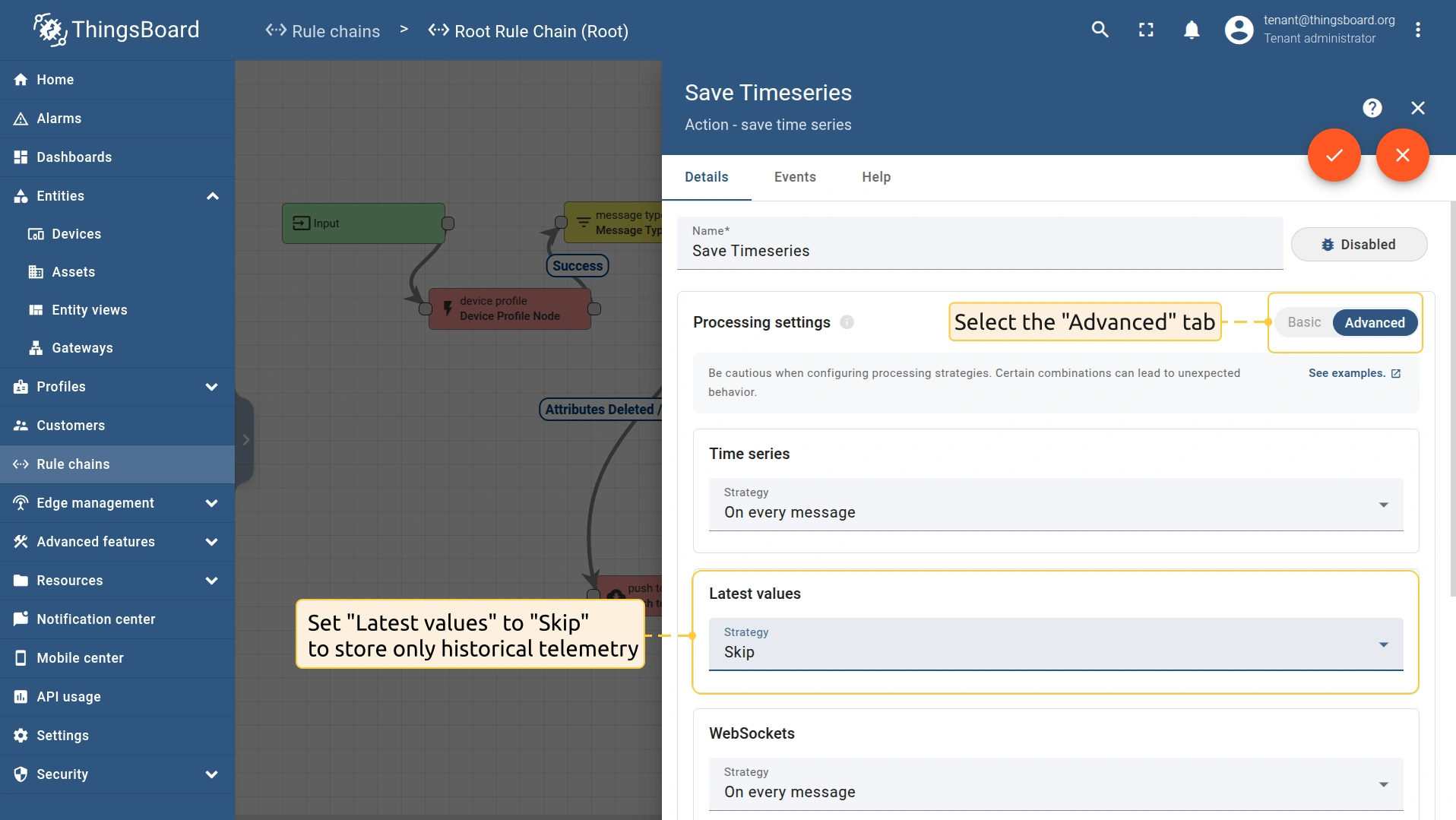
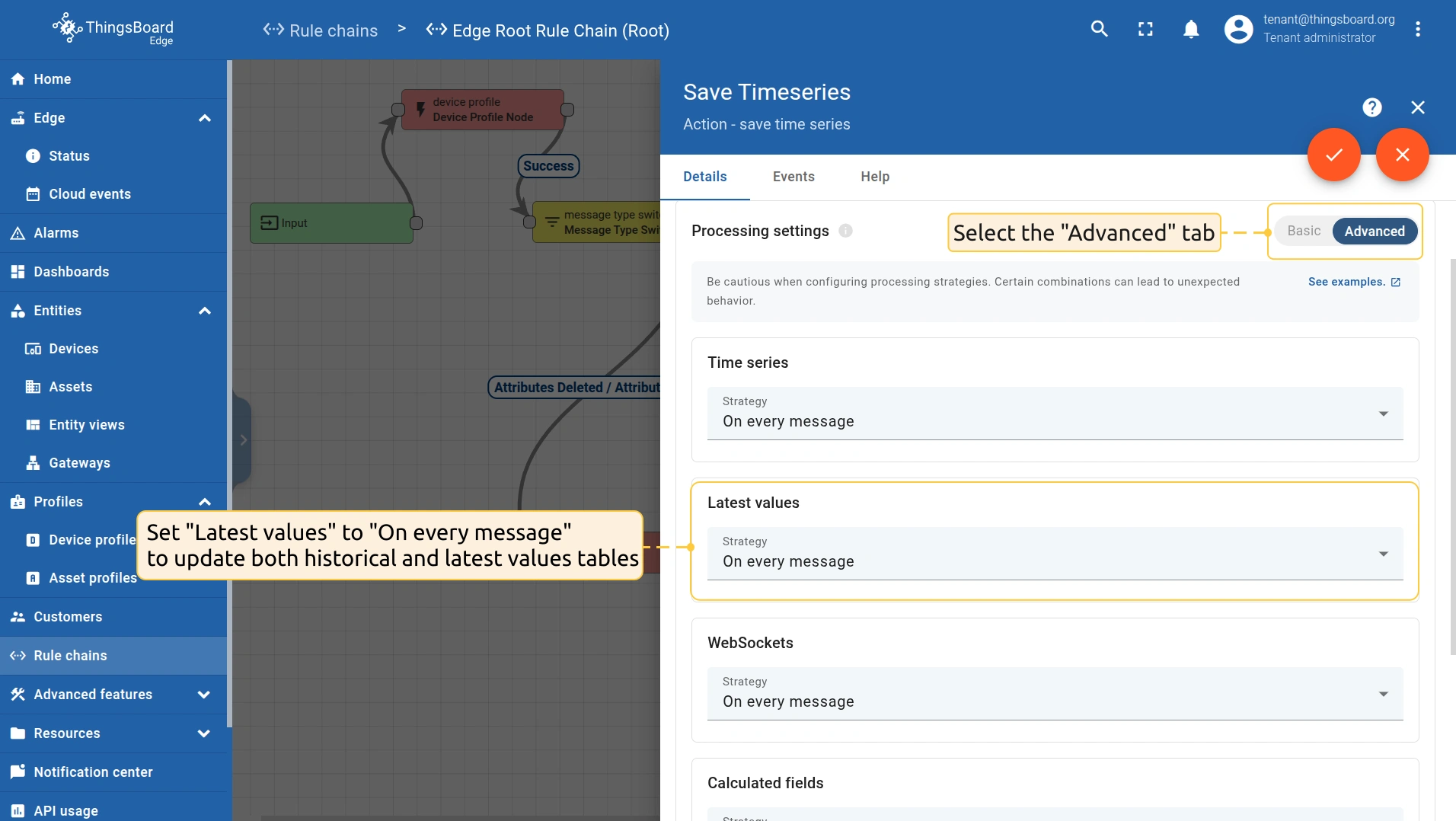
- To store both the latest and historical telemetry, route telemetry to the “save timeseries” rule node and set Latest values to “On every message”. This will write to and update both the timeseries and latest values tables.
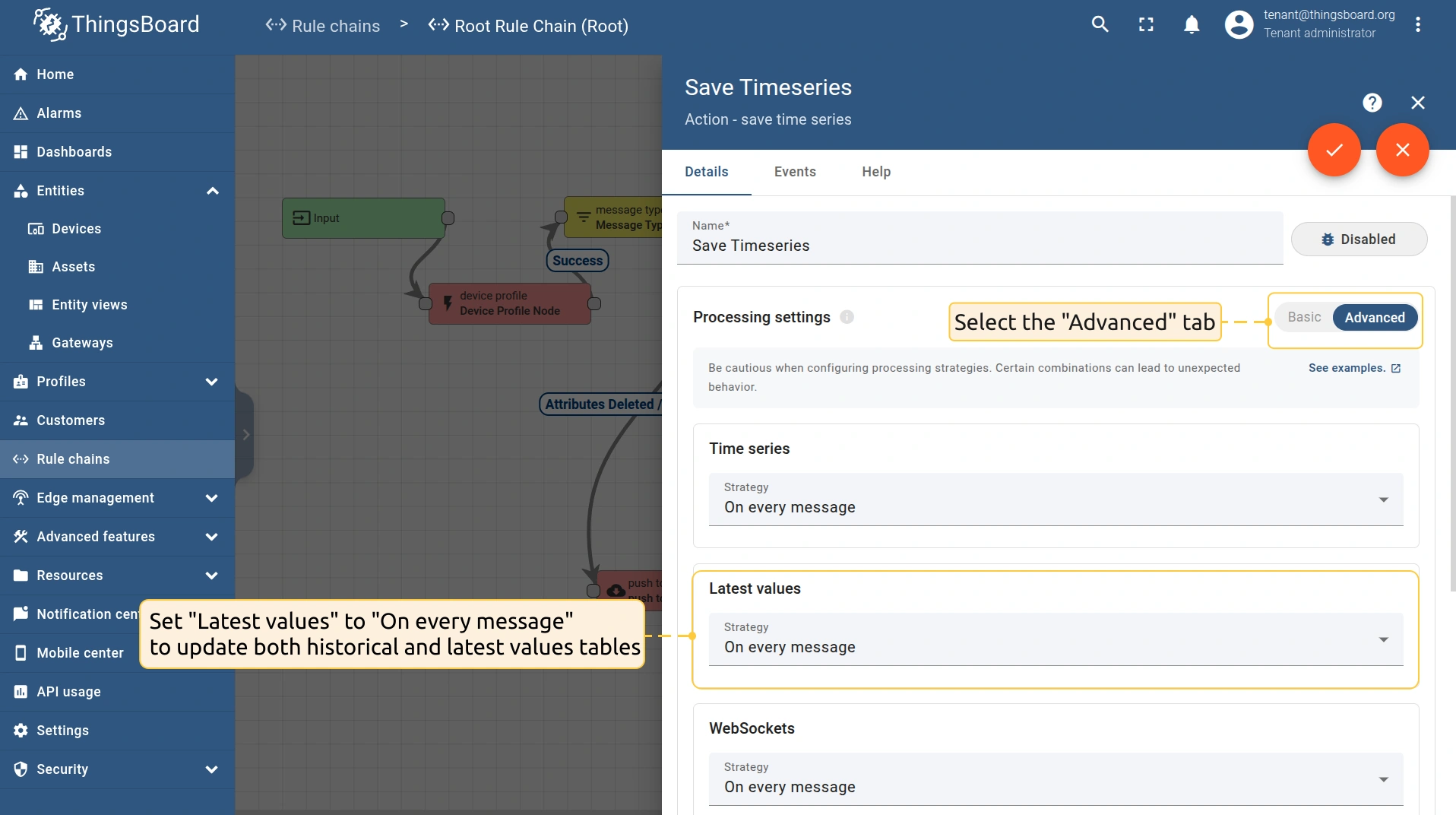
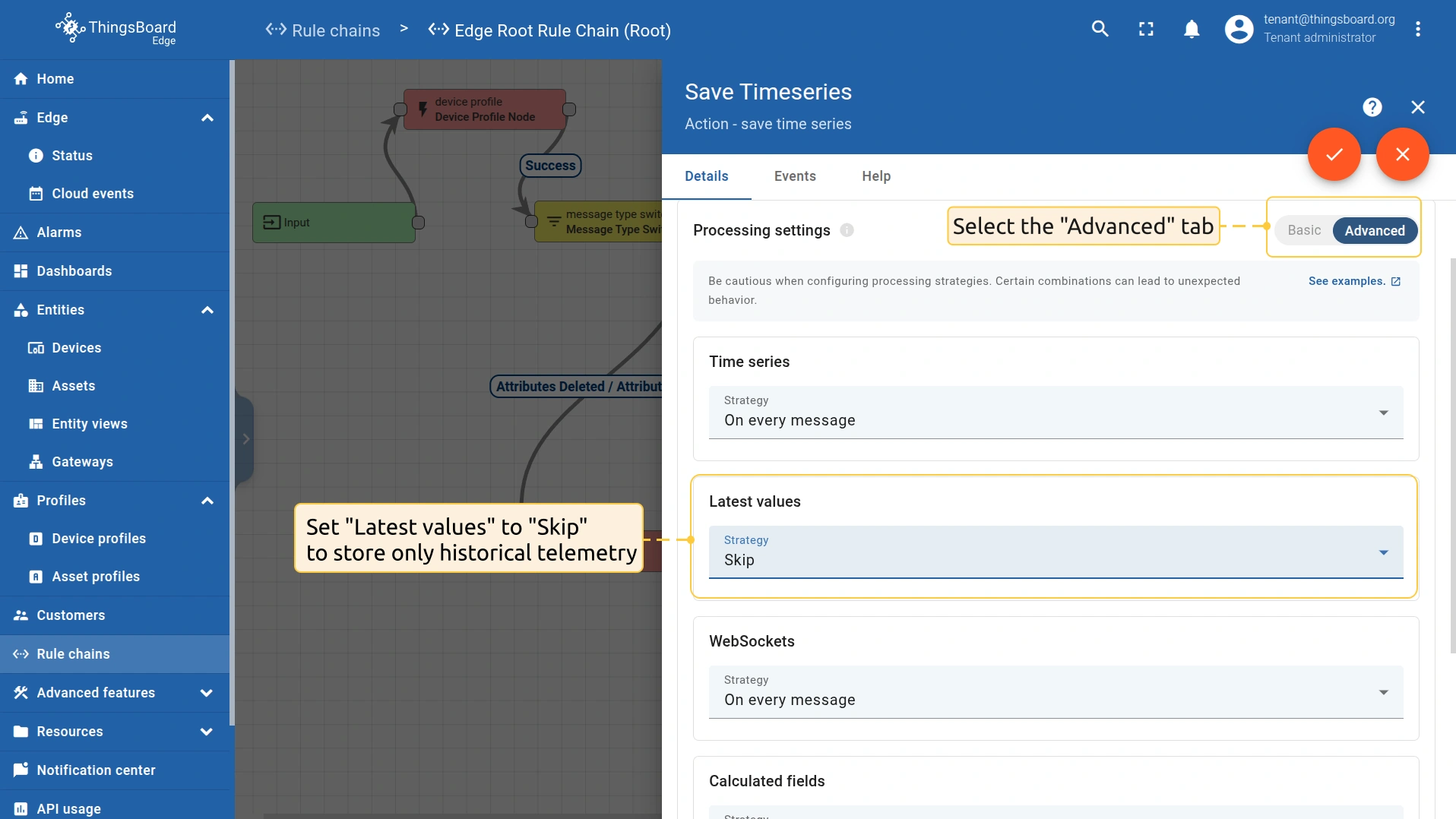
- To store only historical telemetry, route telemetry to the “save timeseries” rule node and set Latest values to “Skip”. This will update only the timeseries table. The latest values table will remain unchanged.
Cloud → Edge sync
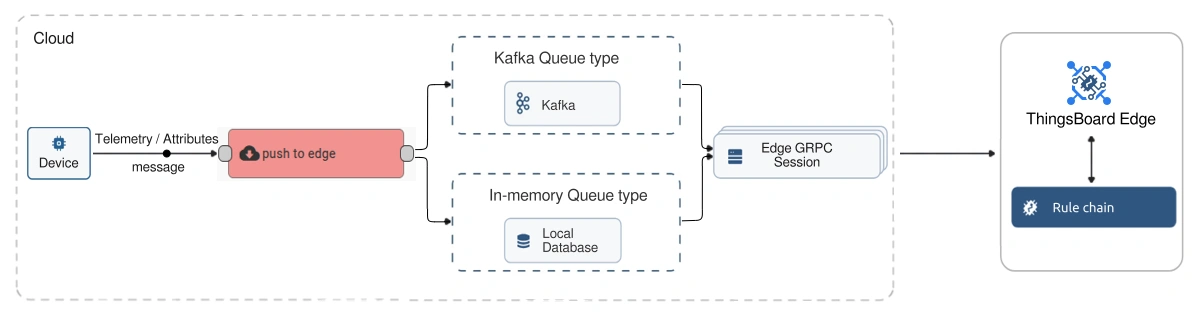
Similarly, Cloud synchronizes data using the “push to edge” rule node within a Cloud rule chain.
The node converts the message into an Edge Event and stores it in the Edge queue on the Cloud (either a local database or Kafka, depending on the queue type). The event is then asynchronously pushed to the target Edge. Once it reaches the Edge instance, it is handled by a corresponding rule chain on the Edge.
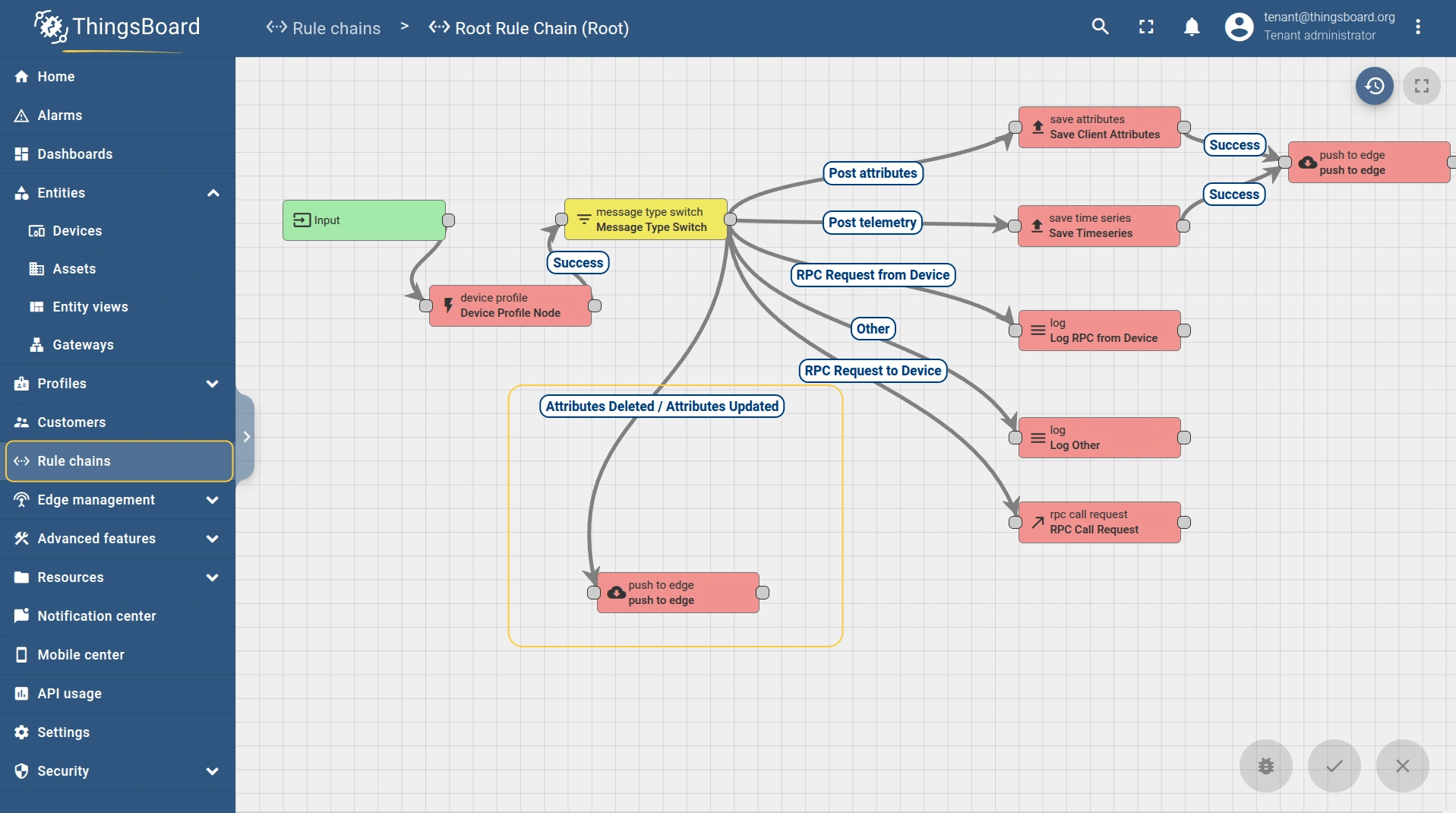
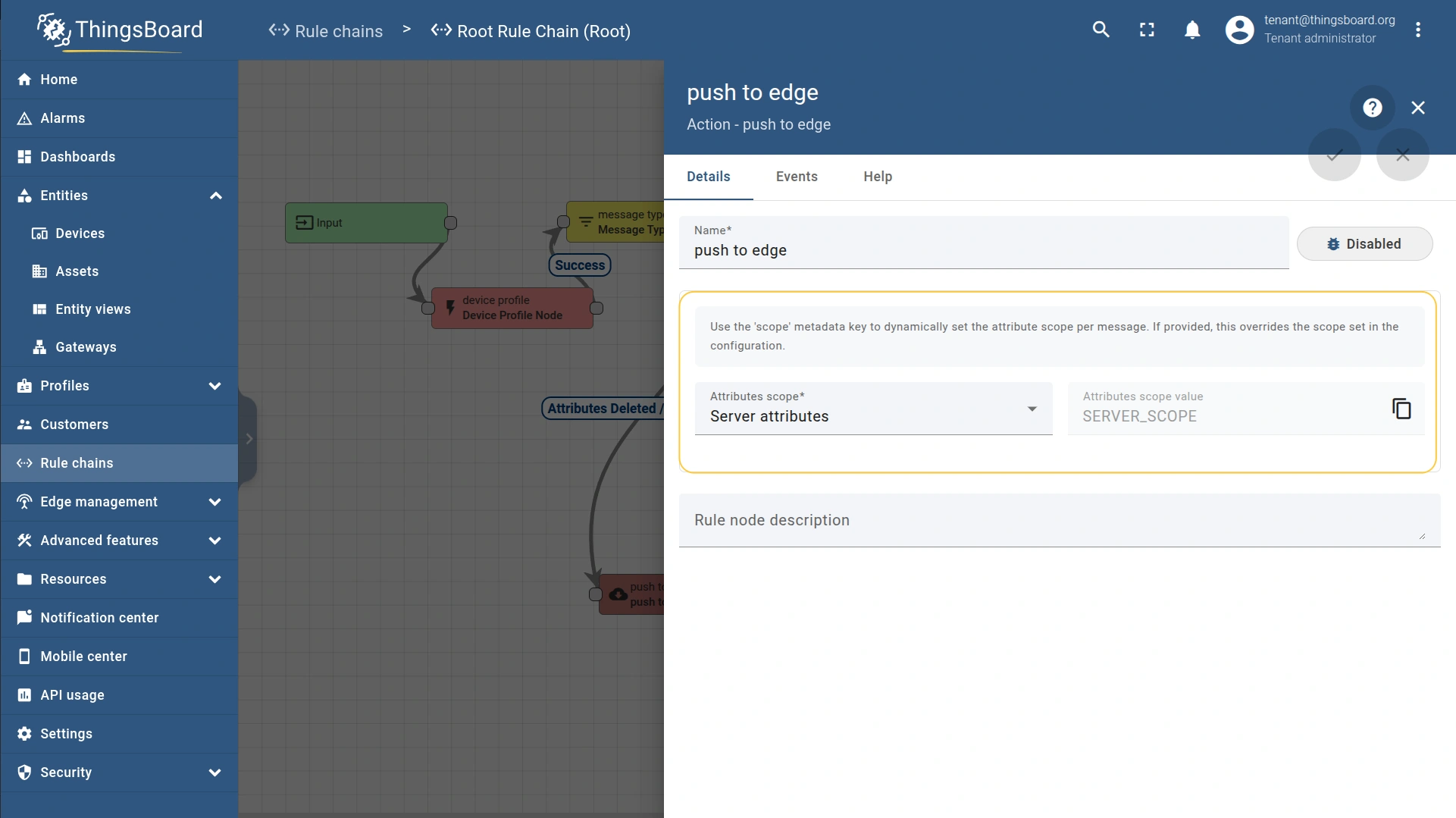
- To propagate attribute changes, connect the Attributes updated and Attributes deleted relations to the “push to edge” node. This ensures both the key–values and the scope travel with the event.
- The attribute scope type (Server attributes, Shared attributes, or Client attributes) is also configured within the “push to edge” node.
Data storage on the Edge
Edge always keeps a local, authoritative copy of the data it ingests or receives from the Cloud. This enables offline operation and quick local reactions.
- When data is sent from a device to the Edge:
Edge writes the telemetry data to the local database first. Based on your rule chain configuration, Edge decides whether to push it to the Cloud
-
If an Edge event arrives from the Cloud:
- To store both the latest and historical telemetry, route telemetry to the “save timeseries” rule node and set Latest values to “On every message”. This will write to and update both the timeseries and latest values tables.
- To store only historical telemetry, route telemetry to the “save timeseries” rule node and set Latest values to “Skip”. This will update only the timeseries table. The latest values table will remain unchanged.
Next Steps
-
Getting started guide - Provide quick overview of main ThingsBoard Edge features. Designed to be completed in 15-30 minutes:
-
Installation guides - Learn how to setup ThingsBoard Edge on various available operating systems and connect to ThingsBoard Server.
-
Edge Rule Engine:
-
Rule Chain Templates - Learn how to use ThingsBoard Edge Rule Chain Templates.
-
Provision Rule Chains from cloud to edge - Learn how to provision edge rule chains from cloud to edge.
-
- Security:
- gRPC over SSL/TLS - Learn how to configure gRPC over SSL/TLS for communication between edge and cloud.
-
Features:
-
Edge Status - Learn about Edge Status page on ThingsBoard Edge.
-
Cloud Events - Learn about Cloud Events page on ThingsBoard Edge.
-
-
Use cases:
-
Manage alarms and RPC requests on edge devices - This guide will show how to generate local alarms on the edge and send RPC requests to devices connected to edge:
-
Data filtering and traffic reduce - This guide will show how to send to cloud from edge only filterd amount of device data:
-
- Roadmap - ThingsBoard Edge roadmap.