Scaling P2P messaging to 1M msg/sec with persistent MQTT clients
Point-to-point (P2P) communication is one of the core MQTT patterns, enabling devices to exchange messages directly in a one-to-one manner. This pattern is especially relevant for IoT scenarios requiring reliable, targeted messaging — private messaging, command delivery, and other direct interaction use cases.
This test evaluates how well TBMQ performs with persistent DEVICE clients in a P2P scenario. Persistent DEVICE clients are well-suited for P2P messaging because they use a shared Kafka topic, reducing load on Kafka, while using Redis to ensure reliable delivery even when a client is temporarily offline. The tests scaled infrastructure while progressively increasing load from 200,000 to 1,000,000 messages per second, demonstrating TBMQ’s scalability and consistent performance.
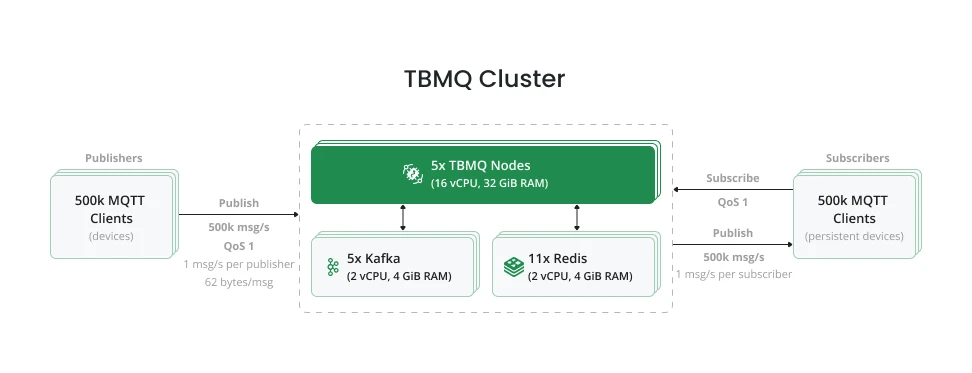
Test methodology
Section titled “Test methodology”Five tests measured performance, efficiency, and latency, with a maximum throughput of 1M msg/sec. Throughput refers to the total number of messages per second, including both incoming and outgoing. The environment was deployed on an AWS EKS cluster and scaled horizontally as workload increased.
Each test ran for 10 minutes, using an equal number of publishers and subscribers. Both operated with QoS 1.
Subscribers used clean_session=false so all messages could be retained during offline periods and delivered on
reconnect. Publishers sent 62-byte messages to unique topics europe/ua/kyiv/$number once per second; subscribers
subscribed to europe/ua/kyiv/$number/+, where $number is the unique identifier for each publisher–subscriber
pair.
Test agent setup
Section titled “Test agent setup”The test agent simulated publishers and subscribers. It consisted of a cluster of performance test pods (runners) and an orchestrator pod. Two runner types — publishers and subscribers — were deployed with equal pod counts. The table below shows pods per instance and instances deployed for one runner type across throughput levels.
| Throughput (msg/sec) | Pods/Instance | EC2 instances |
|---|---|---|
| 200k | 5 | 1 |
| 400k | 5 | 1 |
| 600k | 10 | 1 |
| 800k | 5 | 2 |
| 1M | 5 | 4 |
The orchestrator ran on a separate EC2 instance that also hosted Kafka Redpanda console and Redis Insight for monitoring and coordination. This configuration enabled the test agent to adapt to rising traffic demands while addressing infrastructure constraints, such as port limitations.
Infrastructure overview
Section titled “Infrastructure overview”Hardware specifications:
| Service | TBMQ | Kafka | Redis | AWS RDS (PostgreSQL) |
|---|---|---|---|---|
| Instance type | c7a.4xlarge | c7a.large | c7a.large | db.m6i.large |
| vCPU | 16 | 2 | 2 | 2 |
| Memory (GiB) | 32 | 4 | 4 | 8 |
| Storage (GiB) | 20 | 30 | 8 | 20 |
| Network (Gbps) | 12.5 | 12.5 | 12.5 | 12.5 |
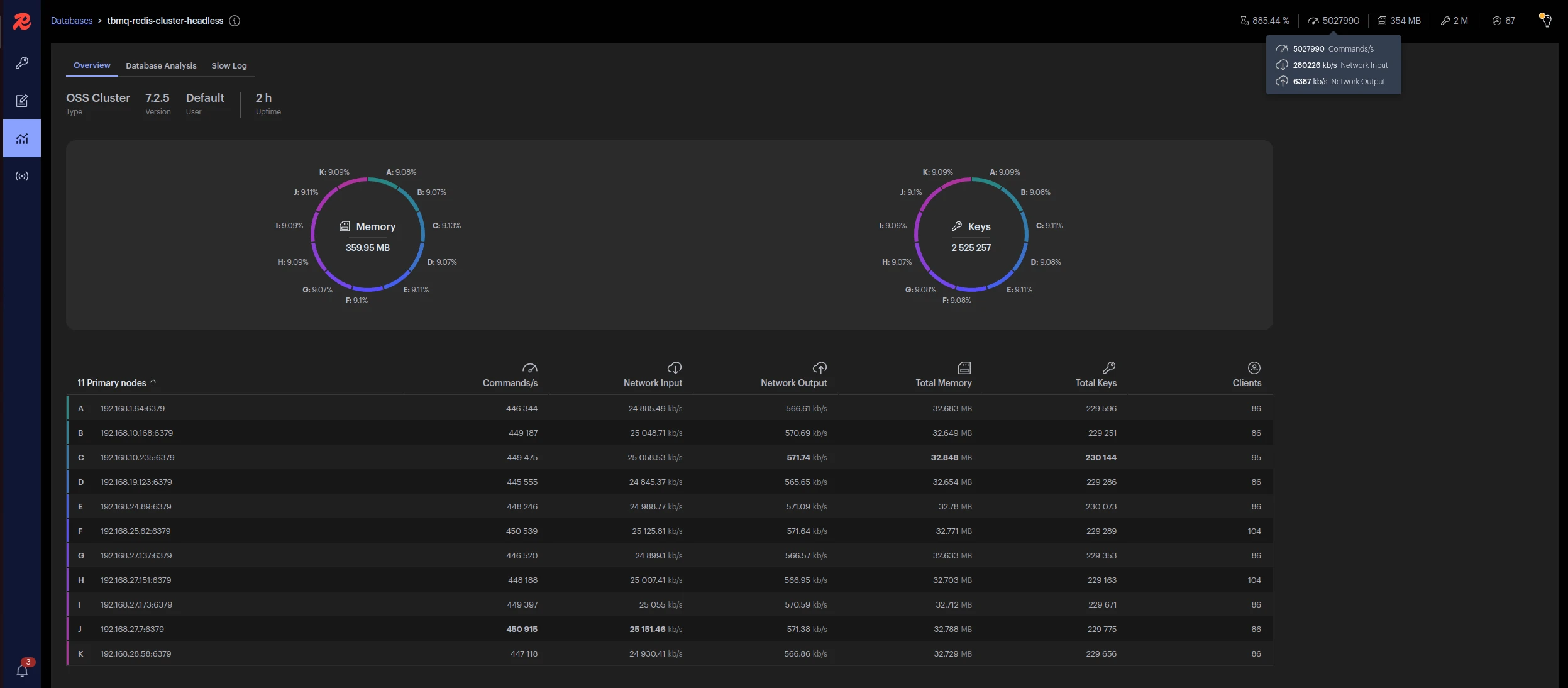
Redis master nodes without replicas were used to reduce costs during load testing.
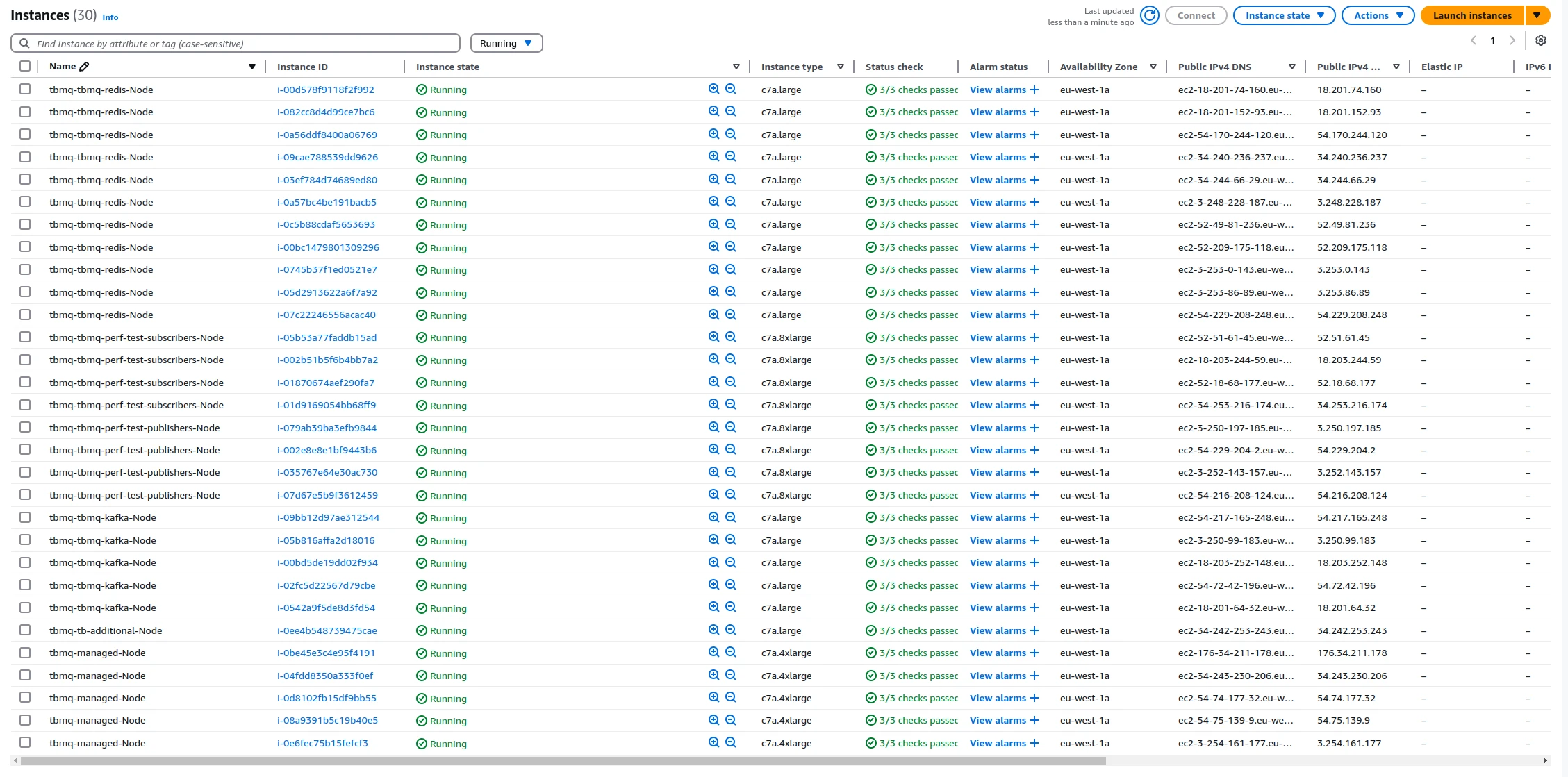
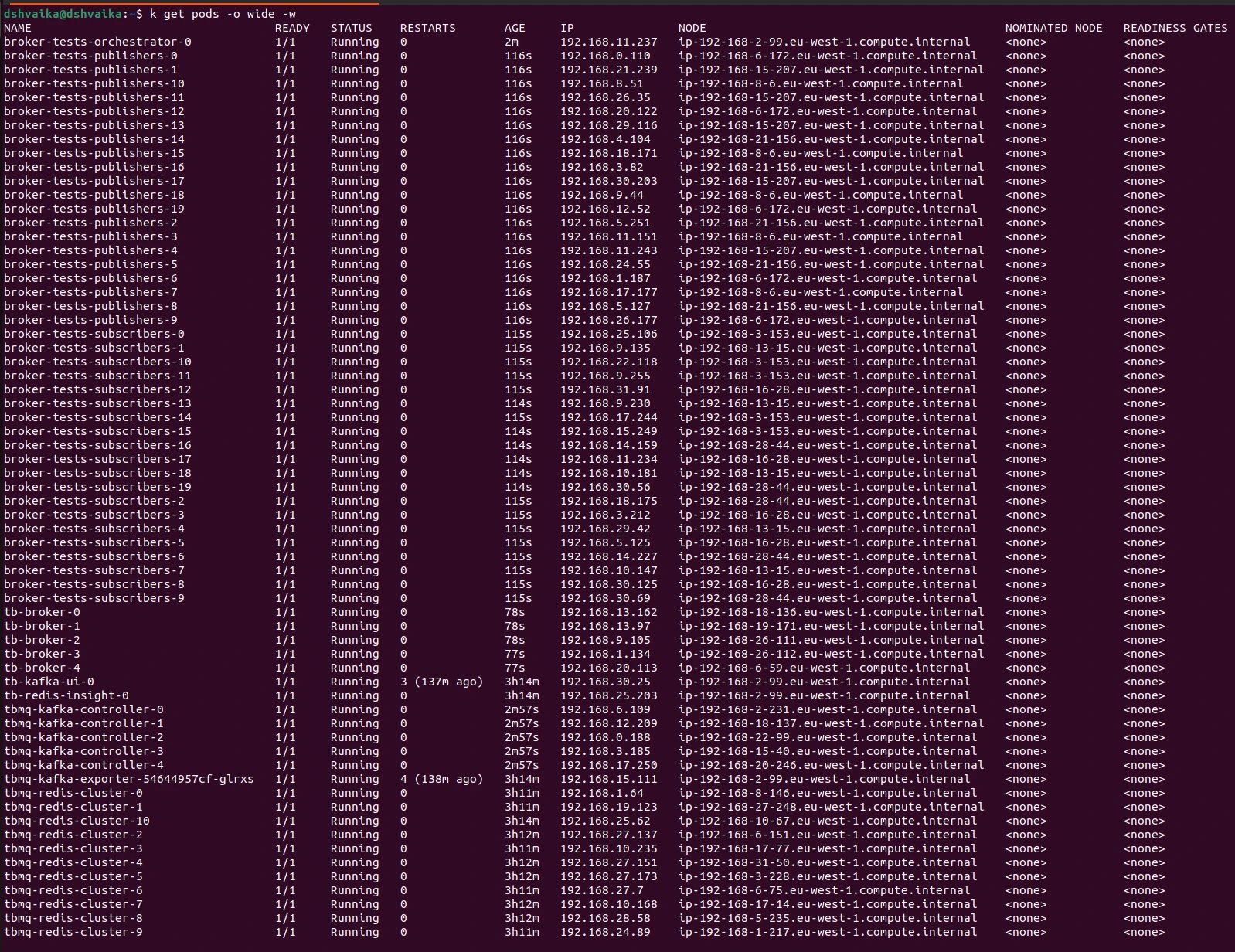
EC2 instances and pod distribution (final 1M msg/sec test):
Performance tests
Section titled “Performance tests”Tests ran in phases from 200k to 1M msg/sec, incrementing by 200k. TBMQ brokers and Redis nodes were scaled at each phase; for the 1M test, Kafka nodes were also scaled.
| Throughput (msg/sec) | Publishers/Subscribers | TBMQ nodes | Redis nodes | Kafka nodes |
|---|---|---|---|---|
| 200k | 100k | 1 | 3 | 3 |
| 400k | 200k | 2 | 5 | 3 |
| 600k | 300k | 3 | 7 | 3 |
| 800k | 400k | 4 | 9 | 3 |
| 1M | 500k | 5 | 11 | 5 |
Key takeaways:
- Scalability: TBMQ demonstrated linear scalability by incrementally adding nodes at higher workloads.
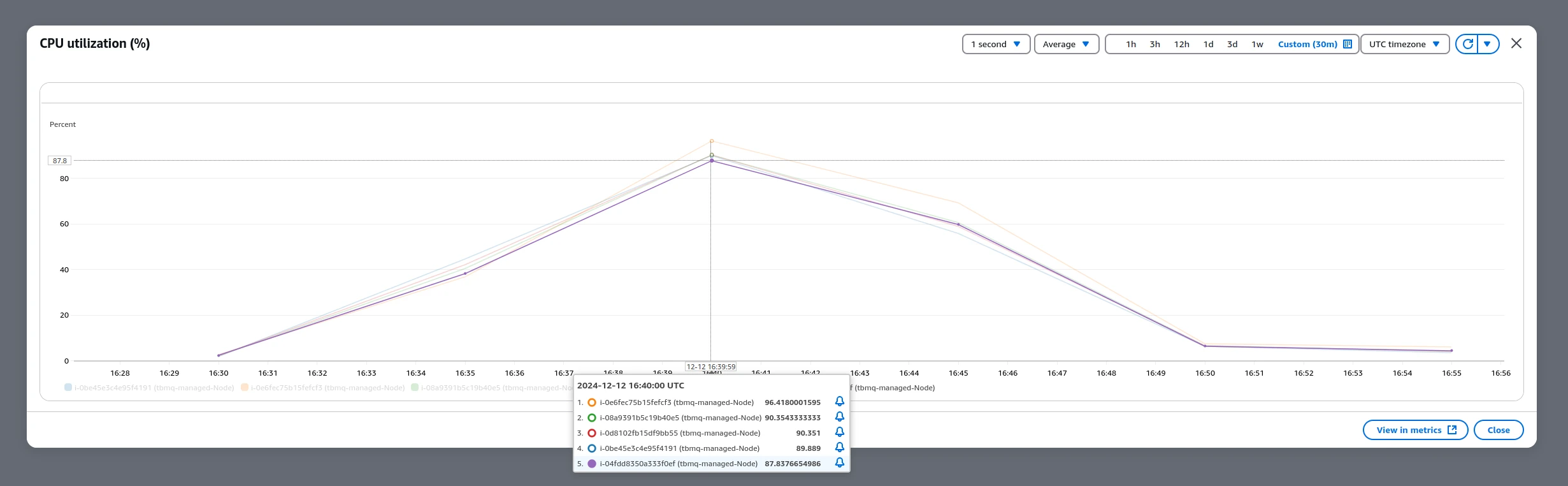
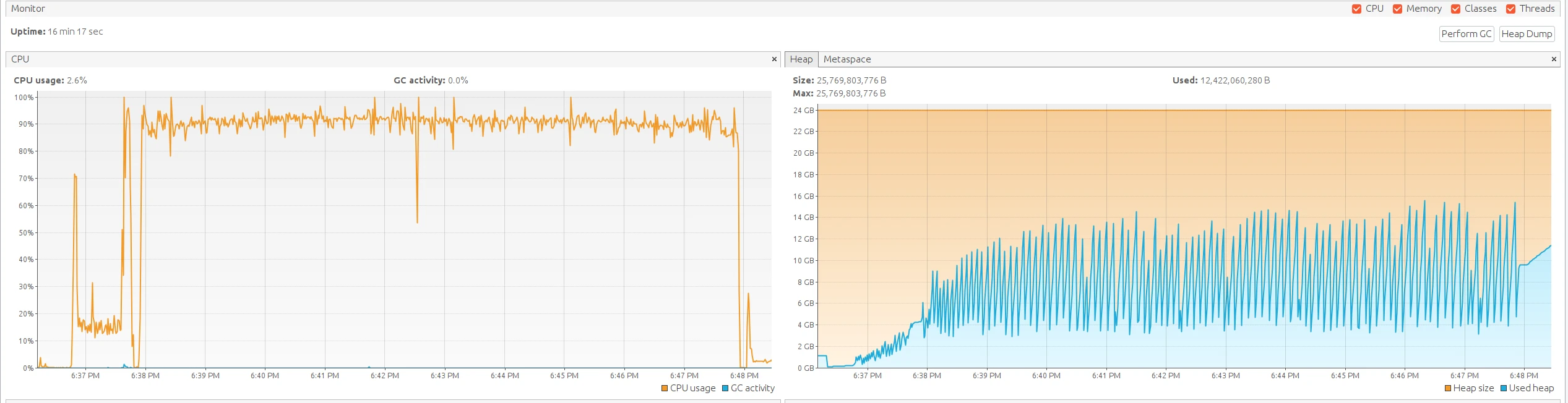
- Efficient resource utilization: CPU utilization on TBMQ nodes stayed consistently around ~90% across all phases.
- Latency: End-to-end latency remained within two-digit millisecond bounds — predictable given the QoS 1 level applied to both publishers and persistent subscribers. Publisher ACK latency stayed within single-digit milliseconds across all phases.
- Throughput efficiency: ~8,900 msg/sec per CPU core, calculated by dividing total throughput by total CPU cores.
Final 1M msg/sec test results:
| QoS | Msg latency avg | Pub ACK avg | TBMQ CPU avg | Payload |
|---|---|---|---|---|
| 1 | ~75 ms | ~8 ms | 91% | 62 bytes |
Where:
- TBMQ CPU avg: average CPU utilization across all TBMQ nodes
- Msg latency avg: average time from publisher transmission to subscriber receipt
- Pub ACK avg: average time from publisher transmission to PUBACK receipt
How to repeat the test
Section titled “How to repeat the test”Refer to the AWS cluster installation guide for step-by-step instructions on deploying TBMQ on AWS.
- TBMQ branch with test scripts and parameters
- Performance testing tool for P2P scenarios
- P2P test configuration README
For the P2P scenario, the testing tool was improved to autogenerate publisher and subscriber configurations instead of loading them from a JSON configuration file.
Migrating from Jedis to Lettuce
Section titled “Migrating from Jedis to Lettuce”One significant challenge during testing was the Jedis library’s synchronous nature becoming a bottleneck under high throughput. Each Redis command was sent and processed sequentially — the system had to wait for each command to complete before issuing the next, limiting Redis’s ability to handle concurrent operations.
The team migrated to the Lettuce client, which uses Netty for asynchronous communication. Unlike Jedis, Lettuce allows multiple commands to be sent in parallel without waiting for completion, enabling non-blocking operations and better resource utilization. This made it possible to fully utilize Redis’s performance capabilities, especially under high message loads. The migration required rewriting a substantial portion of the codebase to transition from synchronous to asynchronous workflows, including restructuring how Redis commands were issued and handled. Careful planning and rigorous testing ensured that these changes maintained system reliability and correctness.
Future optimizations
Section titled “Future optimizations”TBMQ currently uses Lua scripts in Redis to process messages for DEVICE persistent clients, ensuring atomic operations for saving, updating, and deleting messages — crucial for maintaining data consistency. One script is executed per client to comply with Redis Cluster constraints (all keys accessed in a script must reside in the same hash slot).
A potential optimization is adjusting the hashing mechanism for client IDs to intentionally group more clients into the same Redis hash slots, increasing the likelihood of batching operations into a single Lua script execution per hash slot and allowing the scripts to handle multiple clients simultaneously. This would reduce overhead and improve Redis efficiency while adhering to cluster constraints.
Conclusion
Section titled “Conclusion”Across all five tests, TBMQ demonstrated linear scalability and efficient resource utilization. As workload increased from 200k to 1M msg/sec, the system maintained reliable message delivery and sufficiently low latency for point-to-point messaging scenarios.
These capabilities make TBMQ well-suited for IoT use cases requiring high-performance one-to-one communication with guaranteed delivery. Follow the project on GitHub to stay updated on further improvements.
Was this helpful?